 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 查看负载前监控数据
- 查看负载后监控数据
- 第一步:查看集群资源监控
- 第二步:查看节点用量排行
- 第三步:查看节点监控
- 查看资源状态
- 查看监控指标
- 第三步:查看容器组监控
- 第四步:查看容器监控
KubeSphere 监控提供逐级钻取能力,对资源的监控从以下两条线提供多维度的监控指标,用户可以很方便地掌握资源和业务的运行情况并快速定位故障。
- 管理员视角:Cluster -> Node -> Pod -> Container
- 用户视角:Cluster -> Workspace -> Namespace -> Workload/Pod -> Container
我们在 示例五 - 设置弹性伸缩 (HPA) 中设置过一个 Load-generator 循环地向 hpa-example 应用发送无限的查询请求访问应用的服务,模拟多个用户同时访问该服务,造成了 CPU 负载迅速上升。那么在本示例中,将演示通过多维度监控逐级地去排查是哪一个节点的哪些容器造成的资源消耗上升,判断该监控图表的趋势是否符合预期。
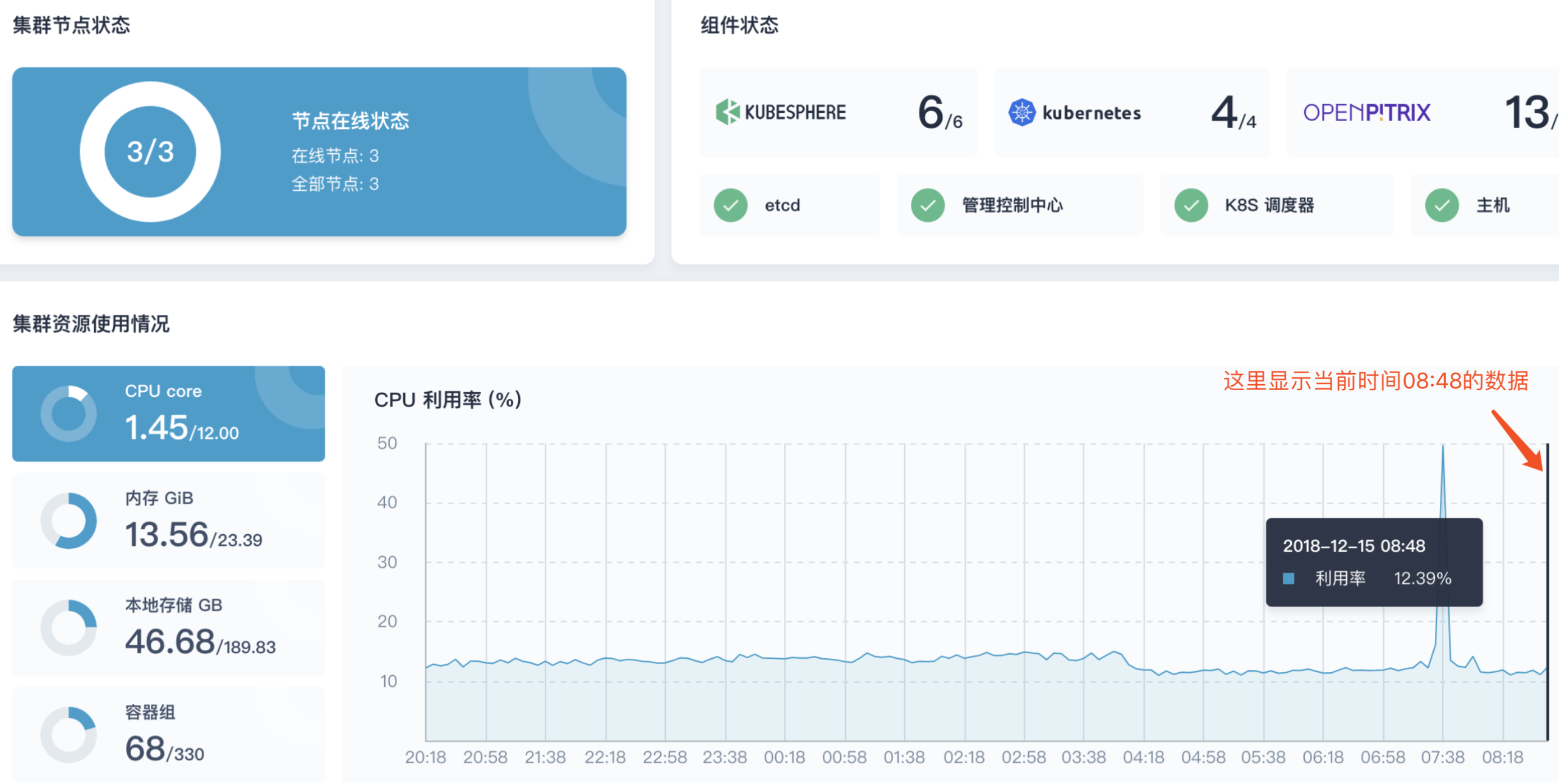
查看负载前监控数据
在 Load-generator 创建之前,我们先记录一下此时集群的监控数据。目前集群一共三个节点,集群资源的监控数据记录如下:
| 初试时间 | CPU 使用率 | 内存 (GiB) | 本地存储 (GB) | 容器组 |
|---|---|---|---|---|
| 08:48 | 12.39 % | 13.56 | 46.68 | 68 |
查看负载后监控数据
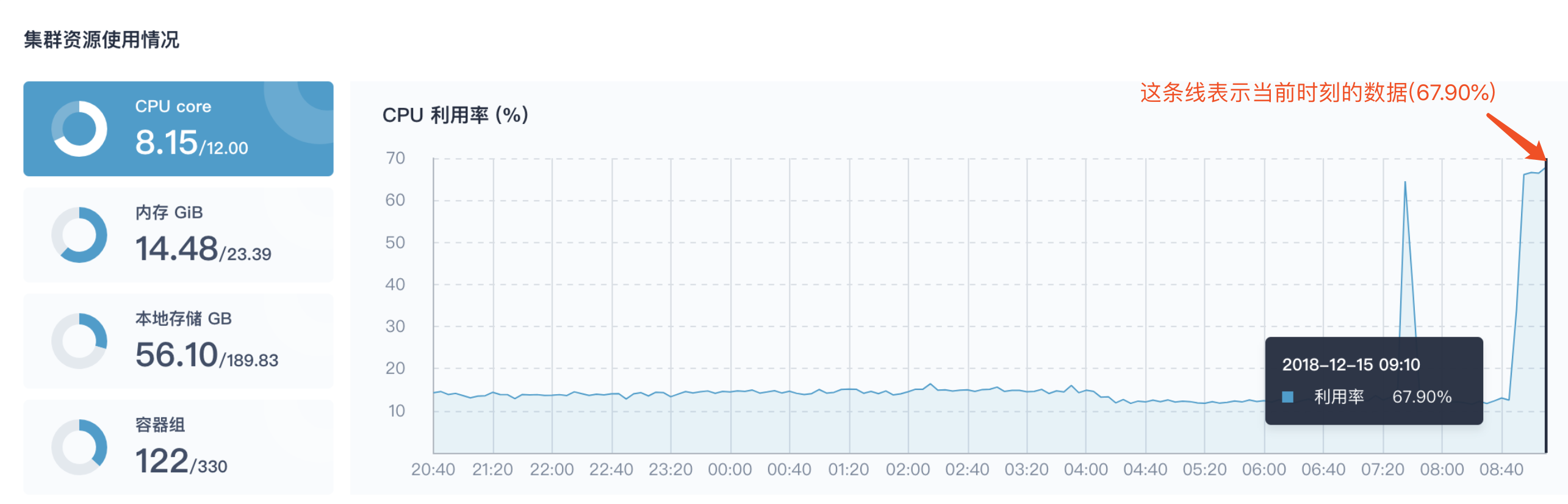
第一步:查看集群资源监控
此时,参考示例五创建 HPA 和 Load-generator,并将设置了 HPA 的所有副本固定在某一个节点,待 Load-generator 开始工作后,理论上集群的 CPU 使用会有一个突增,在 监控中心 → 物理资源 → 集群状态 的 集群资源使用状况 监控数据中,我们发现 Load-generator 开始工作后集群 CPU 使用率的曲线在 08:48 ~ 09:00 有一个非常明显的上升,CPU 使用率在 09:00 已经上升至 66.1 %,09:10 高达 67:90 %。这种情况就需要引起集群管理员的特别注意了,具体是什么工作负载或服务造成 CPU 利用率突增,要去判断造成资源消耗突然增大的根源具体是在哪一个节点或企业空间下哪个项目的工作负载,并根据这一时段的监控数据状况去判断该情况是否属于正常,并观察该资源消耗的趋势是继续保持上升还是趋于平稳。
| 监控时间 | CPU 使用率 | 内存 (GiB) | 本地存储 (GB) | 容器组 |
|---|---|---|---|---|
| 09:10 | 67.90 % | 14.48 | 56.10 | 122 |
此时,最好的办法就是先判断这些资源负载的上升主要来自于哪个节点,该节点的 CPU 和内存使用量以及磁盘使用空间是否已经接近饱和或达到极限,是否存在因资源不足造成对宿主机的威胁。
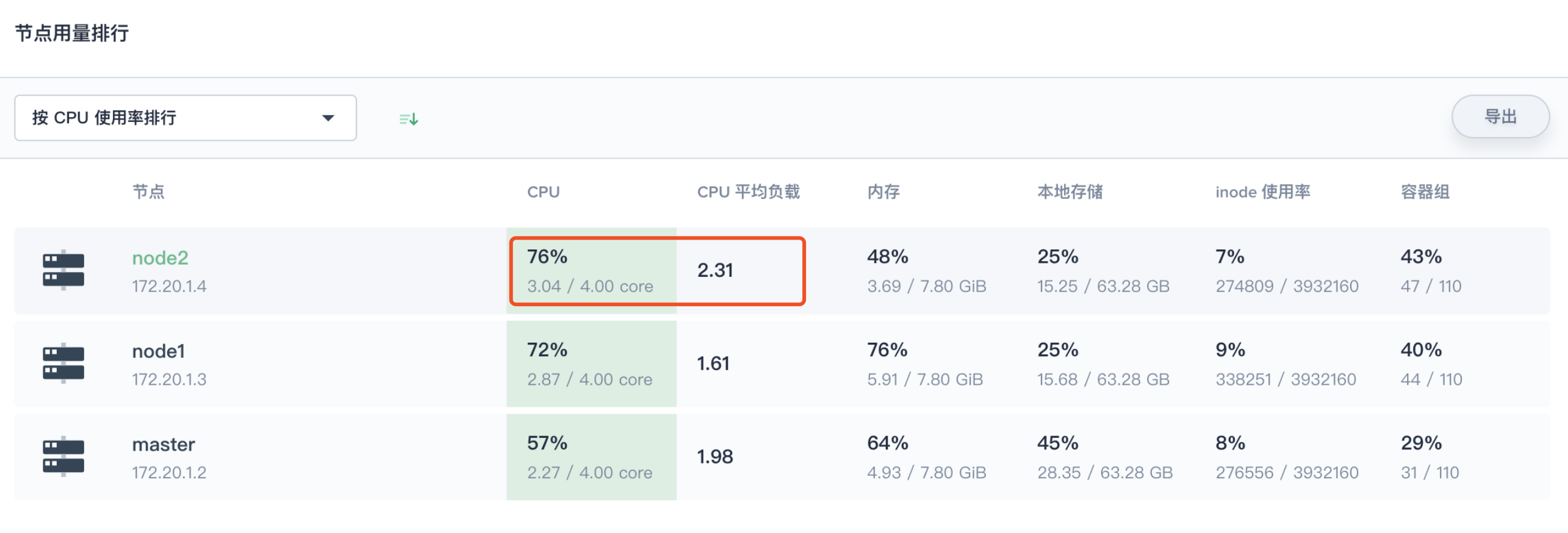
第二步:查看节点用量排行
点击 节点用量排行,按 CPU 使用率、CPU 平均负载排行,可以很方便地发现 node2 节点的这两项指标都排在第一位。那么就需要定位到 node2 查看该节点具体运行了哪些工作负载以及它们运行状况的监控数据。
第三步:查看节点监控
查看资源状态
点击 node2 或从 基础设施 → 主机 中查看主机列表,即可看到所有节点在当前时刻的资源使用量。例如在主机列表中,node2 的 CPU 使用量和容器组数量是排在第一位的。
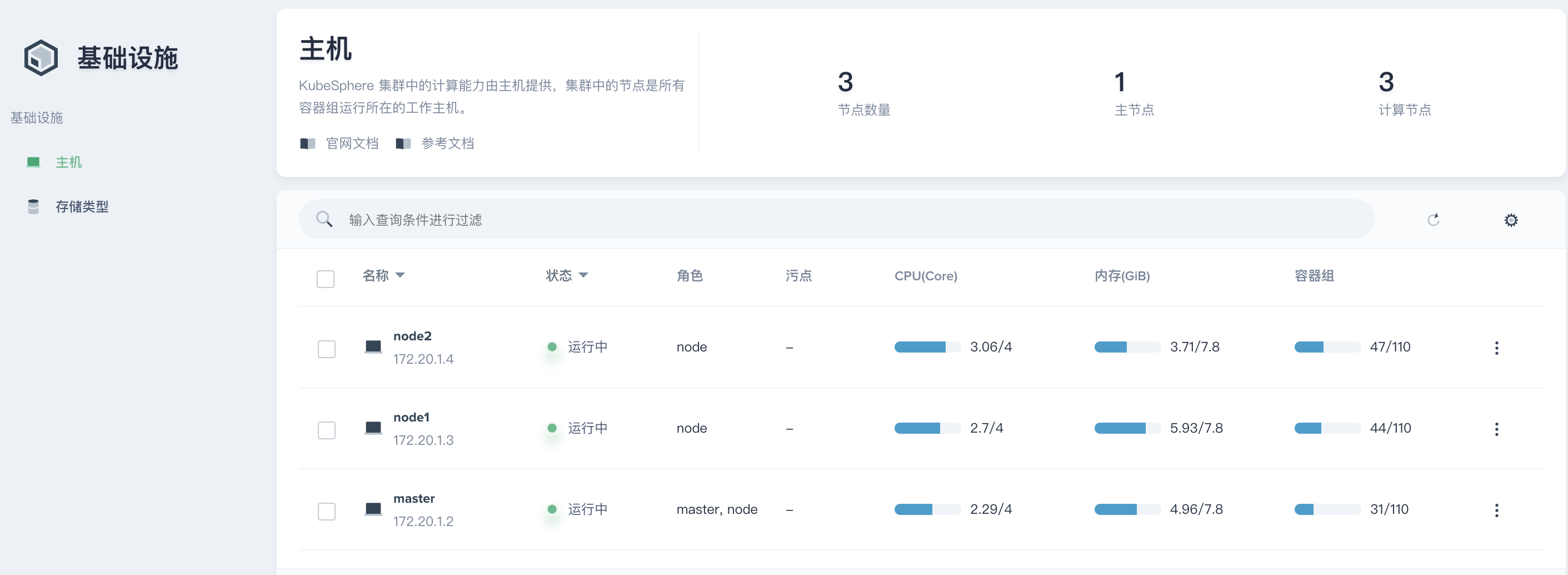
进入 node2 详情页,首先可以查看主机的资源状态和节点状态,其中资源状态四项指标的饼图显示均为正常 (若资源不足饼图则显示黄色或红色),并且通过节点状态的五个属性也可以判断出当前节点的 CPU 、内存或存储的压力并未超过该节点的最大负荷,关于节点的五个属性释义,详见 主机管理。

注意:如果此时发现节点的资源状态或节点状态的监控数据显示当前节点的 CPU 或内存使用量已经接近总量,没有充足的资源可供新的 Pod 调度到该节点运行,那么便需要为该节点添加污点并设置 effect 规则,不允许新的 Pod 调度到该节点,详见 污点管理。
查看监控指标
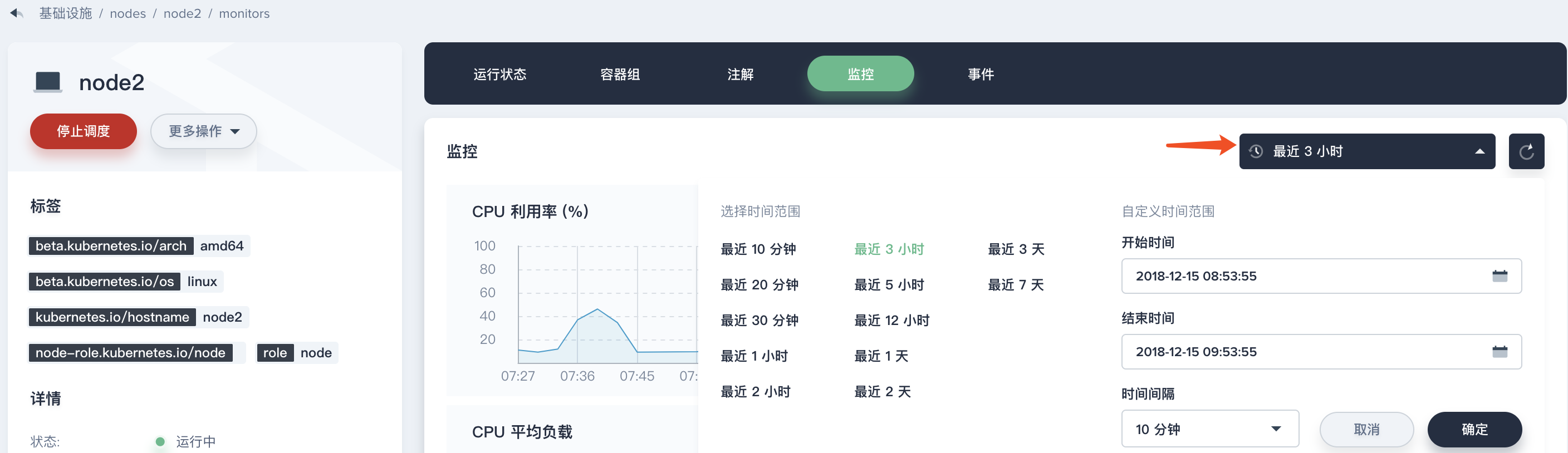
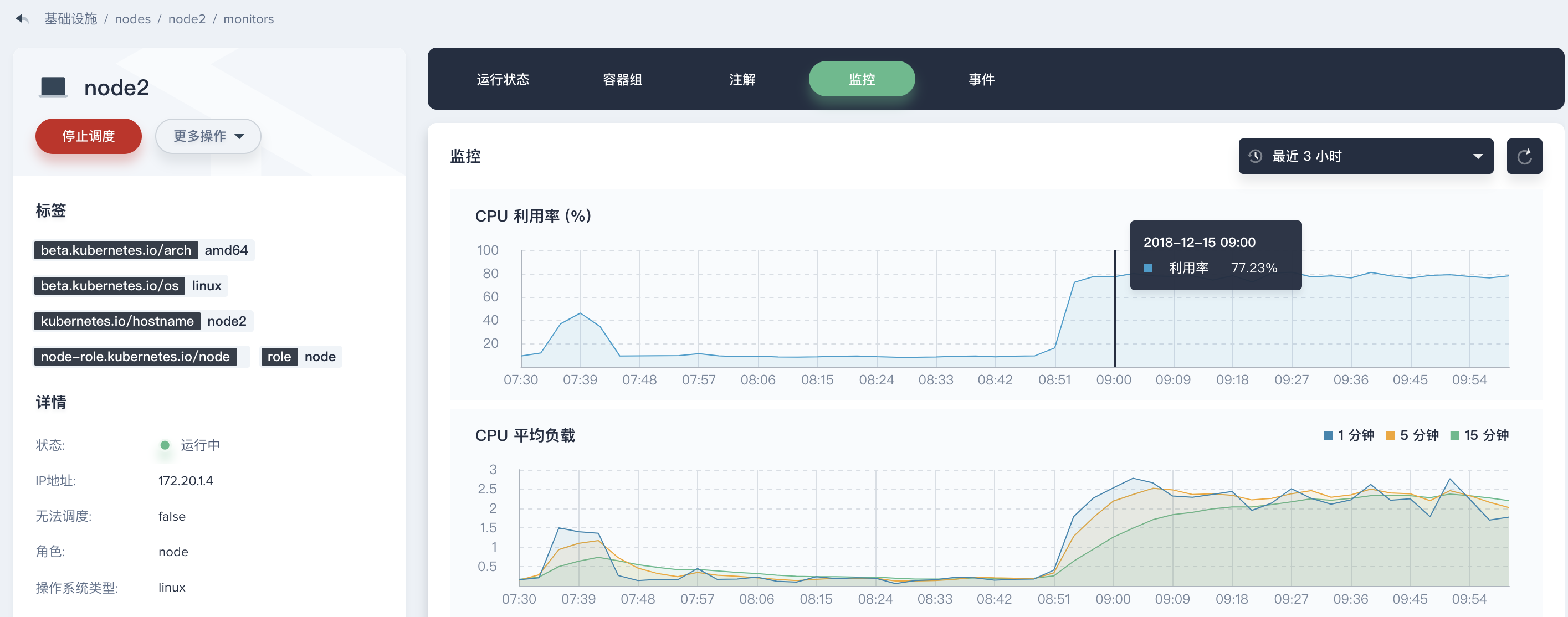
在上面的 Tab 中点击 监控,查看 node2 的监控详情,右侧支持按时间范围和间隔查看历史监控数据,我们查看最近三小时的数据可以发现从初始时间 08:48 到 09:00 时段 CPU 使用率和 CPU 平均负载同时有一个非常明显的上升,这与我们在同一时间段看到的 集群资源使用状况 监控数据的趋势是基本一致的,因此可以判断造成资源消耗突然上升的工作负载或服务大概率就落在 node2 中,那么我们可以进一步去查看具体是企业空间下的哪个项目中的工作负载引起的。
说明:在 09:00 到现在时刻,可以发现 CPU 利用率和平均负载有一个趋于平缓的曲线,该情况即可反馈两类信息:
- 当前节点在 09:00 以后的状态已恢复正常工作状态,但由于工作负载的数量增加,其使用率要比之前高出很多,可以继续保持观察
- 该曲线在 09:00 以后趋于平稳是因为弹性伸缩 (HPA) 开始工作,使 Nginx 服务后端的 Pod 数量增加来共同处理 Load-generator 的循环请求,这也是 HPA 的工作原理,详见 示例二 - 弹性伸缩工作原理。
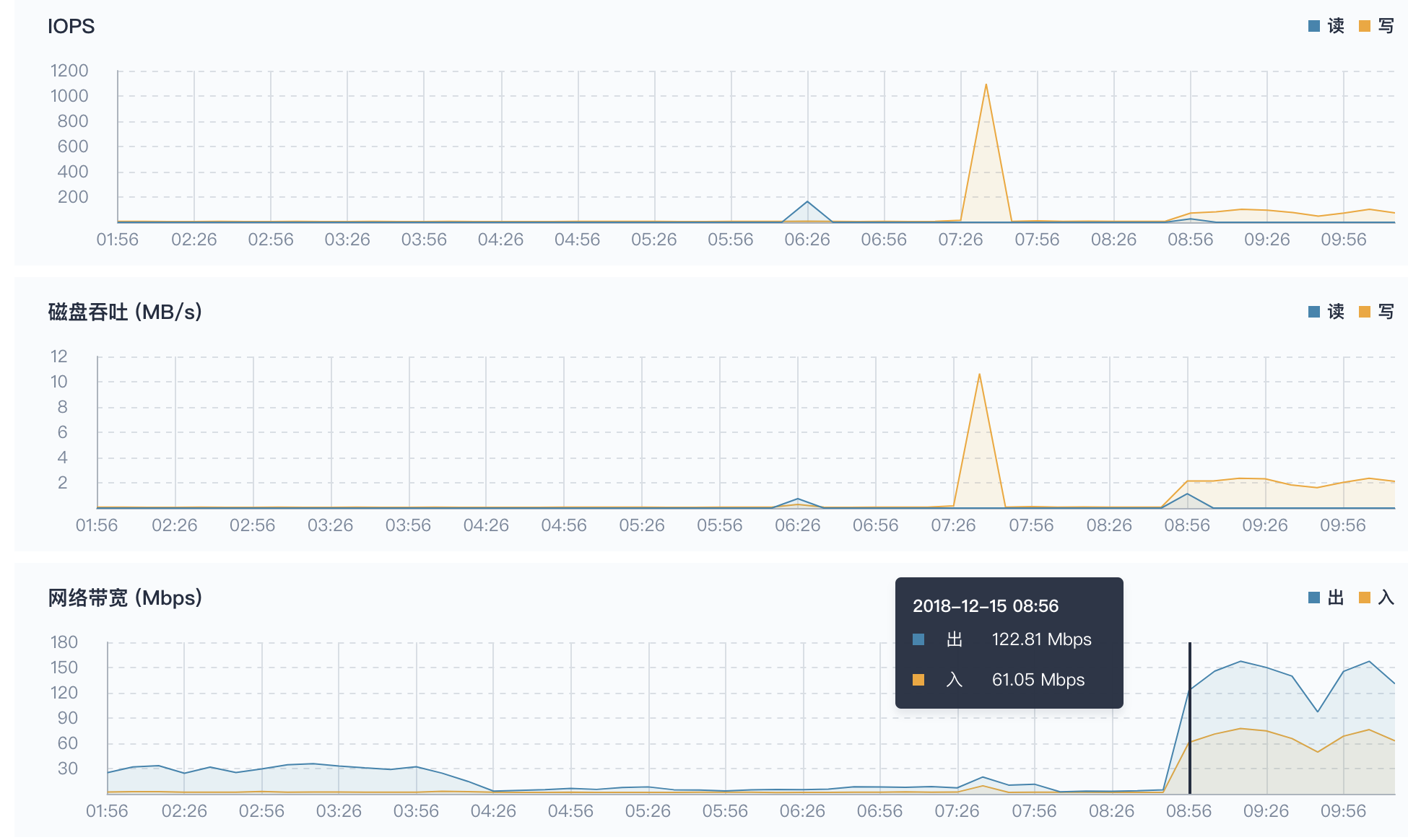
下拉查看 node2 节点的 IOPS, 磁盘吞吐 读写和 网络带宽 出入的监控曲线,在初始时间 08:48 至 09:00 这个时间段也有较为明显的上升趋势,之后渐渐趋于平稳。
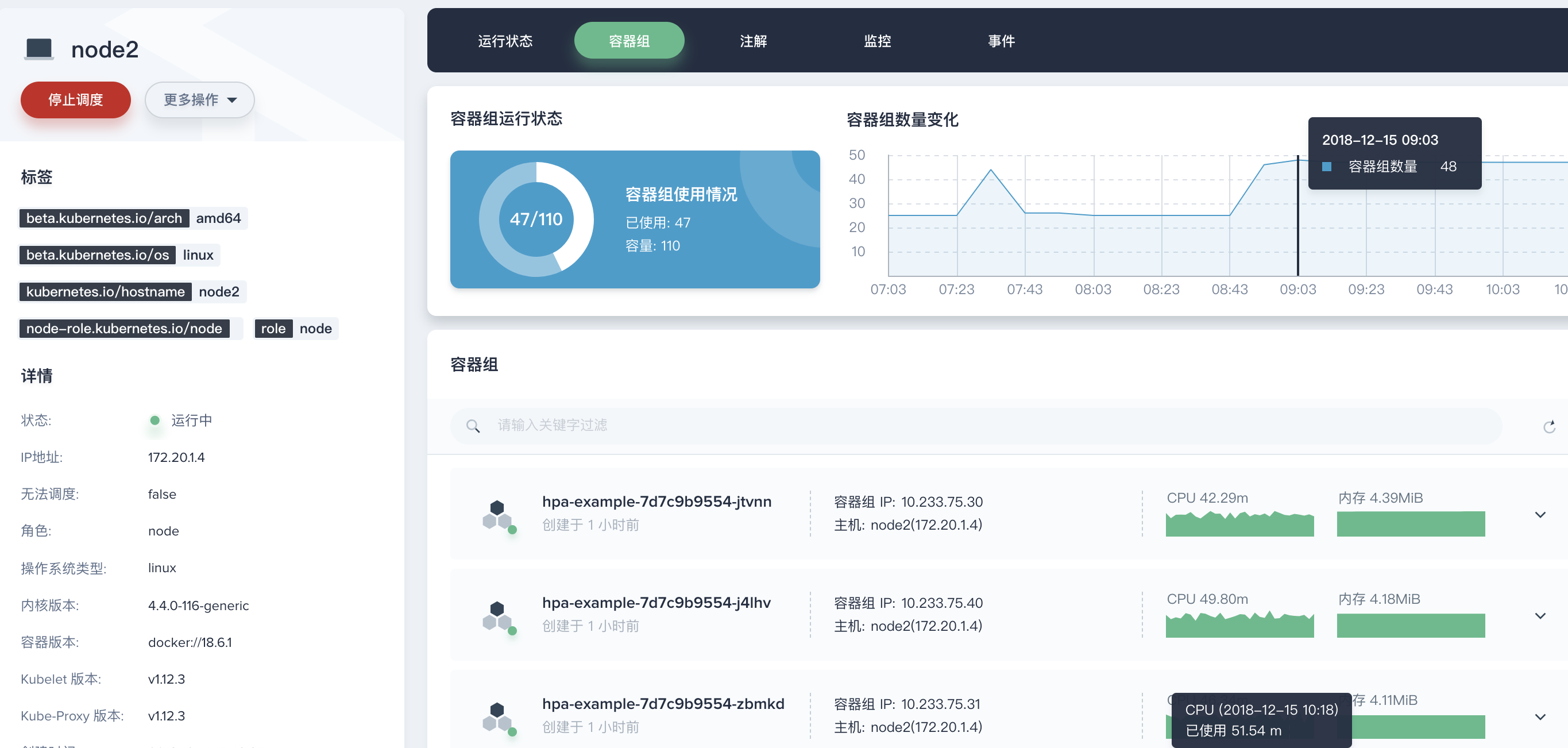
第三步:查看容器组监控
在上面的 Tab 点击 容器组,查看 node2 上运行的所有容器组 (Pod) 的监控数据。通过 容器组数量变化 的监控曲线可以发现在 08:48 至 09:00 这个时间新增了 20 个容器组调度到了 node2,因此可以初步判断 CPU 使用率的突然上升是由于容器组数量的增加而不是由于物理资源异常造成的。在容器组列表中,可以查看所有 30 分钟内容器组的 CPU 和内存的使用量,理论上在 08:48 到 09:00 这个时间段,最初创建的 2 个 hpa-example 容器组的 CPU 使用量也会有一个明显的上升趋势,因此点击查看其中一个容器组的监控数据。
查看其中一个 CPU 使用量曲线有明显上升趋势的容器组 hpa-example-7d7c9b9554-zbmkd,右上角选择自定义时间范围为最近 2 小时,可以看到该容器组的 CPU 使用量 和 网络流出速率 在相同时间段内有较为明显的上升,这与第三步中阐述的现象是相符的,因此可以进一步查看该 Pod 中的容器监控状态,并判断其是否运行正常。
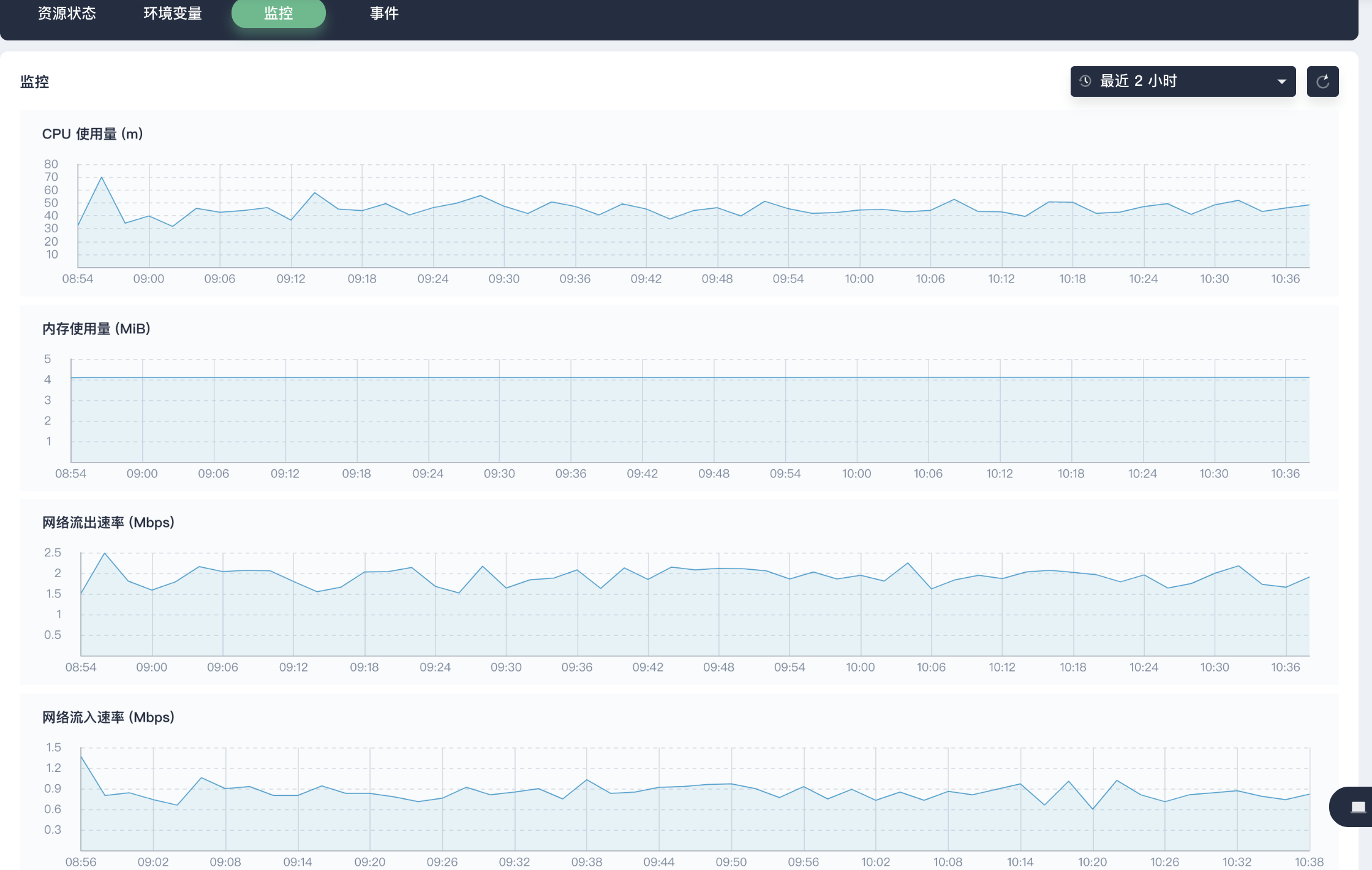
第四步:查看容器监控
在上面的 Tab 点击 资源状态,点击容器进入容器详情页,查看容器的监控数据,在 08:48 ~ 09:10 也有一段明显的上升,但往后也基本趋于平稳。这个趋势与 HPA 的过程也是相符合的。
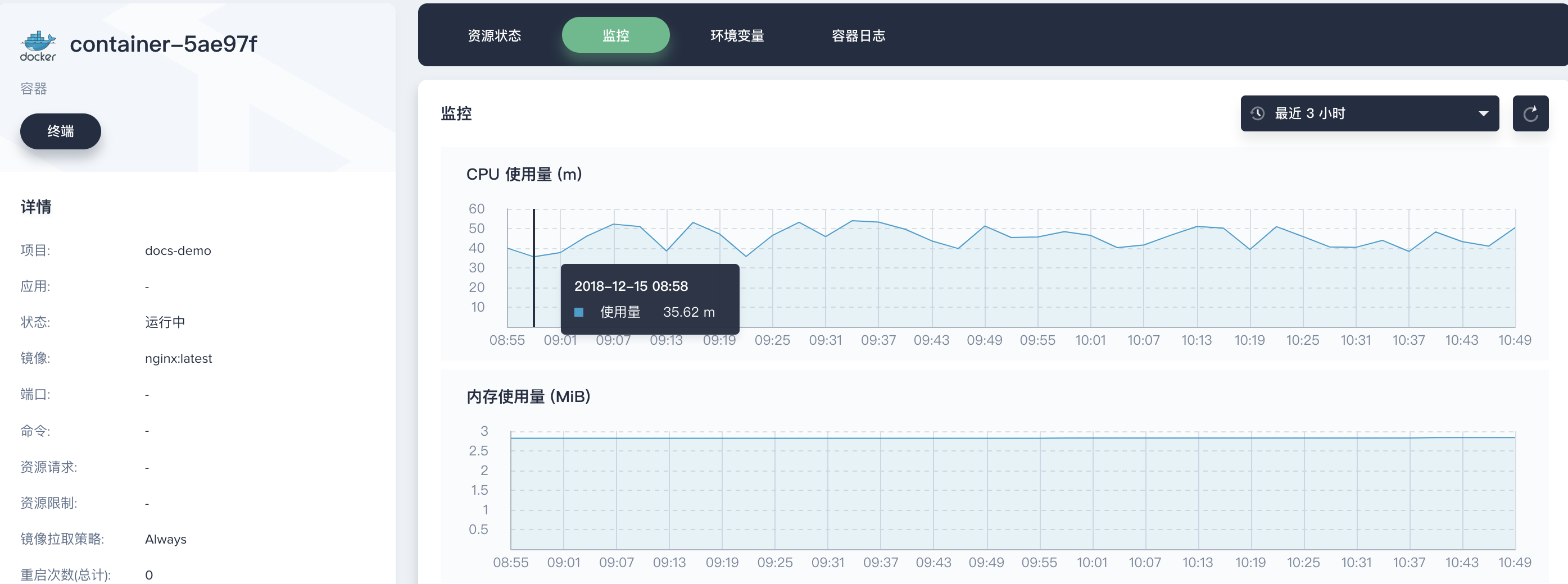
本示例说明了如何通过多维度监控,逐级地去排查问题和定位原因。
