 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- Factorization Machines
- 1. 算法介绍
- Factorization Model
- Factorization Machines as Predictors
- 2. FM on Angel
- 3. 运行和性能
- 1. 算法介绍
Factorization Machines
因子分解机(Factorization Machine, FM)是由Steffen Rendle提出的一种基于矩阵分解的机器学习算法。它可对任意的实值向量进行预测。其主要优点包括: 1) 可用于高度稀疏数据场景;2) 具有线性的计算复杂度。
1. 算法介绍
Factorization Model
- Factorization Machine Model
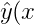 =b+\sum{i=1}^n{w_ix_i}+\sum{i=1}^n\sum_{j=i+1}^n
=b+\sum{i=1}^n{w_ix_i}+\sum{i=1}^n\sum_{j=i+1}^n
其中: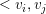 是两个k维向量的点乘:
是两个k维向量的点乘:
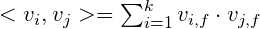
模型参数为: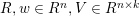 其中
其中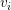 表示用k个因子表示特征i,k是决定因子分解的超参数。
表示用k个因子表示特征i,k是决定因子分解的超参数。
Factorization Machines as Predictors
FM可以被用于一系列的预测任务,比如说:
- 分类:
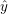 可以直接被用作预测值,优化准则为最小化最小平方差。
可以直接被用作预测值,优化准则为最小化最小平方差。 - 回归:可以用的符号做分类预测,参数通过合页损失函数或者逻辑回归随时函数估计。
2. FM on Angel
FM算法模型FM算法的模型由两部分组成,分别是wide和embedding,其中wide就是典型的线性模型。最后的输出结果为wide和embedding两部分之和。
FM训练过程 Angel实现了用梯度下降方法优化,迭代得训练FM模型,每次迭代worker和PS上的逻辑如下:
- worker:每次迭代从PS上拉取wide和embedding矩阵到本地,计算出对应的梯度更新值,push到PS
- PS:PS汇总所有worker推送的梯度更新值,取平均,通过优化器计算新的wide和embedding模型并进行更新
FM预测结果:
- 格式:rowID,pred,prob,label
- 说明:rowID表示样本所在的行ID,从0开始计数;pred:样本的预测结果值;prob:样本相对该预测结果的概率;label:预测样本被分到的类别,当预测结果值pred大于0时,label为1,小于0为-1
3. 运行和性能
数据格式 支持libsvm和dummy两种数据格式,其中libsvm格式举例如下:
1 1:1 214:1 233:1 234:1
dummy数据格式为:
1 1 214 233 234
参数说明
- ml.epoch.num:迭代轮数
- ml.feature.index.range:特征索引范围
- ml.model.size:特征维数
- ml.data.validate.ratio:验证集采样率
- ml.data.type:数据类型,分“libsvm”和“dummy”两种
- ml.learn.rate:学习率
- ml.opt.decay.class.name:学习率衰减系类
- ml.opt.decay.on.batch: 是否对每个mini batch衰减
- ml.opt.decay.alpha: 学习率衰减参数alpha
- ml.opt.decay.beta: 学习率衰减参数beta
- ml.opt.decay.intervals: 学习率衰减参数intervals
- ml.reg.l2:l2正则项系数
- action.type:任务类型,训练用”train”,预测用”predict”
- ml.fm.field.num:输入数据领域(field)的个数
- ml.fm.rank:embedding中vector的长度
- ml.inputlayer.optimizer:优化器类型,可选”adam”,”ftrl”和”momentum”
- ml.data.label.trans.class: 是否要对标签进行转换, 默认为”NoTrans”, 可选项为”ZeroOneTrans”(转为0-1), “PosNegTrans”(转为正负1), “AddOneTrans”(加1), “SubOneTrans”(减1).
- ml.data.label.trans.threshold: “ZeroOneTrans”(转为0-1), “PosNegTrans”(转为正负1)这两种转还要以设一个阈值, 大于阈值的为1, 阈值默认为0
- ml.data.posneg.ratio: 正负样本重采样比例, 对于正负样本相差较大的情况有用(如5倍以上)
提交命令 可以通过下面的命令提交FM算法:
../../bin/angel-submit \-Dml.epoch.num=20 \-Dangel.app.submit.class=com.tencent.angel.ml.core.graphsubmit.GraphRunner \-Dml.model.class.name=com.tencent.angel.ml.classification.FactorizationMachines \-Dml.feature.index.range=$featureNum \-Dml.model.size=$featureNum \-Dml.data.validate.ratio=0.1 \-Dml.data.type=libsvm \-Dml.learn.rate=0.1 \-Dml.reg.l2=0.03 \-Daction.type=train \-Dml.fm.field.num=11 \-Dml.fm.rank=8 \-Dml.inputlayer.optimizer=ftrl \-Dangel.train.data.path=$input_path \-Dangel.workergroup.number=20 \-Dangel.worker.memory.mb=20000 \-Dangel.worker.task.number=1 \-Dangel.ps.number=20 \-Dangel.ps.memory.mb=10000 \-Dangel.task.data.storage.level=memory \-Dangel.job.name=angel_l1
