 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- Json配置文件说明
- 1. 数据相关参数
- 2. 模型相关参数
- 3. 训练相关参数
- 4. 默认优化器, 传输函数, 损失函数
- 4.1 默认优化器
- 4.2 默认传输函数
- 5. 网络中的层
Json配置文件说明
由于深度学习参数较多, 用脚本直接指定参数的方式比较麻烦. 从Angel 2.0开始支持用Json文件指定模型参数(注:系统参数仍用脚本配置), 目前Json文件有两个用途:
- 为已有的算法提供参数, 这些算法包括:
- DeepFM
- PNN
- NFM
- Deep and Wide
- 类似于Cafe, 可以用Json自定义新的网络
可用Json文件配置的参数主要有:
- 数据相关参数
- 模型相关参数
- 训练相关参数
- 默认优化器, 传输函数, 损失函数
- 网络中的层
下面一一介绍
1. 数据相关参数
一个完全的数据配置如下:
"data": {"format": "dummy","indexrange": 148,"numfield": 13,"validateratio": 0.1,"sampleratio": 0.2,"useshuffle": true,"translabel": "NoTrans","posnegratio": 0.01}
下面对照说明:
| Json key | 对应配置项 | 说明 |
|---|---|---|
| format | ml.data.type | 输入数据的格式, 有dense, dummy, libsvm三种选择, 默认为dummy |
| indexrange | ml.feature.index.range | 特征维度 |
| numfield | ml.fm.field.num | 输入数据中域的数目. 虽然特征交叉能生成非常高维的数据, 对于一些数据集, 每个样本域的数目是一定的 |
| validateratio | ml.data.validate.ratio | Angel会将输入数据划分成训练集与验证集, 这个参数就是用于指定验证集的比例. 注:所有的验证集匀存于内存, 当数据量特别大时, 可能会OOM |
| sampleratio | ml.batch.sample.ratio | 这个参数是Spark on Angel专用的, Spark用采样的方式生成mini-batch, 这个参数用于指定采样率 |
| useshuffle | ml.data.use.shuffle | 是否在每个epoch前shuffle数据. 注: 当数据量大时, 这一操作非常影响性能, 请慎重使用. 默认为false, 不用shuffle. |
| translabel | ml.data.label.trans.class | 对于二分类, Angel要求标签为(+1, -1), 如果数据集的标簦是(0, 1)则可以用这一参数进行转换, 默认关闭 |
| posnegratio | ml.data.posneg.ratio | Angel也支持采样生成mini-batch, 但方式与Spark不同, Angel先将数据集的正负例分开, 然后分别按比例从正例, 负例中抽样生成mini-batch, posnegratio就是控制mini-batch中正负样本比例的. 这个参数对不平衡数据集的训有帮助. posnegratio默认为-1, 表示不进行采样 |
注: 除了indexrange外, 其它参数都有默认值, 因此都是可选的.
2. 模型相关参数
一个完全的模型配置如下:
"model": {"loadPath": "path_to_your_model_for_loading","savePath": "path_to_your_model_for_saving","modeltype": "T_DOUBLE_SPARSE_LONGKEY","modelsize": 148}
下面对照说明:
| Json key | 对应配置项 | 说明 |
|---|---|---|
| loadpath | angel.load.model.path | 模型加载路径 |
| savepath | angel.save.model.path | 模型保存路径 |
| modeltype | ml.model.type | 模型类型, 指输入层参数在PS上的类型(数据与存储), 同时它也会决定非输入层的数据类型(非输入层的存储类型为dense) |
| modelsize | ml.model.size | 对于整个数据集, 在某些维度上可能没有数据, 特征维度与模型维度不一致. 模型维度是有效数据维度 |
常用的modeltype有:
- T_DOUBLE_DENSE
- T_FLOAT_DENSE
- T_DOUBLE_SPARSE
- T_FLOAT_SPARSE
- T_DOUBLE_SPARSE_LONGKEY
- T_FLOAT_SPARSE_LONGKEY
3. 训练相关参数
一个完全的模型配置如下:
"train": {"epoch": 10,"numupdateperepoch": 10,"batchsize": 1024,"lr": 0.5,"decayclass": "StandardDecay","decayalpha": 0.001,"decaybeta": 0.9}
下面对照说明:
| Json key | 对应配置项 | 说明 |
|---|---|---|
| epoch | ml.epoch.num | 迭代轮数 |
| numupdateperepoch | ml.num.update.per.epoch | 这个参数只对Angel有用, 指每轮迭代中更新参数据的次数 |
| batchsize | ml.minibatch.size | 这个参数只对Spark On Angel有用, 指mini-batch的大小 |
| lr | ml.learn.rate | 学习率 |
| decayclass | ml.opt.decay.class.name | 指定学习率衰减类 |
| decayalpha | ml.opt.decay.alpha | 指定学习率衰减参数据alpha |
| decayalpha | ml.opt.decay.beta | 指定学习率衰减类数据beta |
其中有:
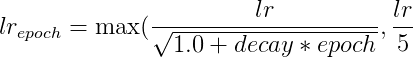 )
)
4. 默认优化器, 传输函数, 损失函数
- Angel允许不同的可训练层使用不同的优化器, 如deep and wide模型中, wide部分使用FTRL, 而deep部分使用Adam.
- 类似地, 也允许不同层使用不同的传递函数(激活函数), 如中间层使用Relu/Sigmoid, 与LossLayer相连的层使用Identity
- Angel可以设置默认的损失函数, 这是为多任务训练设计的, 目前Angel不支持多任务学习, 请忽略
4.1 默认优化器
由于每种优化器都有默认的参数, 所以有两种方式设置默认优化器, 以Momentum为例:
"default_optimizer": "Momentum""default_optimizer": {"type": "Momentum","momentum": 0.9,"reg1": 0.0,"reg2": 0.0}
- 第一种方式: 只指定优化器名称, 优化器参数使用默认的
- 第二种方式: 利用key-value的方式指定优化器的类型(名称)及相关参数. 值得指出的是, 除了名称外, 优化器的参数不是必选的, 如果想使用默认值可以直接忽略某些参数
关于优化器的具体参数, 请参考Angel中的优化器
4.2 默认传输函数
大部分传输函数是没有参数的, 只有少量传输函数, 如dropout, 需要参数. 所以默认传输函数的指定也有两种方式:
"default_transfunc": "Relu""default_transfunc": {"type": "Dropout","actiontype": "train","proba": 0.5}
- 第一种方式: 只指定传递函数的名称, 如果传递函数有参数, 则使用默认参数
- 第二种方式: 利用key-value的方式指定传递函数的类型(名称)及相关参数. 与优化器的参数指定类似, 除了名称外, 传递函数的参数不是必选的, 如果想使用默认值可以直接忽略某些参数.
注: 由于dropout传递函数在训练与测试(预测)中计算方式不一样, 所以要用actiontype表明是哪种场景, train/inctrain, predict.
关于传递函数有更多细节请参考Angel中的传递函数
5. 网络中的层
Angel中的深度学习算法都表示为一个AngelGraph, 而AngelGraph中的节点就是层(Layer). 按层的拓朴结构可分为三类:
- verge: 边缘节点, 只在输入或输出的层, 如输入层与损失层
- linear: 有且仅有一个输入与一个输出的层
- join: 有两个或多个输入, 一个输出的层
注: 虽然Angel的层可以有多个输入, 但最多只有一个输入. 一个层的输出可以作为多个层的输入, 即输出可以”重复消费”.
在Json中, 所有与层相关的参数都放在一个列表中, 如下:
"layers" : [{parameters of layer},{parameters of layer},...{parameters of layer}]
虽然不同的层有不同的参数, 但它们有一些共性:
- 每个layer都有一个名称(name)和一个类型(type):
- name: 是layer的唯一标识, 因此不能重复
- type: 是layer的类型, 实际是就是Layer对应的
类名
- 除了输入层(DenseInputLayer, SparseInputLayer, Embedding)外, 其它层都有”inputlayer”这个参数, 对于join layer, 它有多个输入, 所以它的输入用”inputlayers”指定:
- inputlayer: 对于linear或loss层要指定, inputlayer值是输入层的name
- inputlayers: 对于join层要指定, 用一个列表表示, 其值是输入层的name
- 除Loss层外, 其它层都有输出, 但Angel中不用显式指出, 因为指定了输入关系就同时指定了输出关系. 但是要显式地指出输出的维度:
- outputdim: 输出的维度
- 对于trainable层, 由于它有参数, 所以可以指定优化器, 以”optimizer”为key. 其值与”default_optimizer”的一样
- 对于某些层, 如DenseInputLayer, SparseInputLayer, FCLayer它们还可以有传递函数, 以”transfunc”为key, 其值与”default_tansfunc”的一样
- 对于loss层, 有”lossfunc”, 用于指定损失函数
下面是一个DeepFM的类子:
"layers": [{"name": "wide","type": "SimpleInputLayer","outputdim": 1,"transfunc": "identity"},{"name": "embedding","type": "Embedding","numfactors": 8,"outputdim": 104,"optimizer": {"type": "momentum","momentum": 0.9,"reg2": 0.01}},{"name": "fclayer","type": "FCLayer","outputdims": [100,100,1],"transfuncs": ["relu","relu","identity"],"inputlayer": "embedding"},{"name": "biinnersumcross","type": "BiInnerSumCross","inputlayer": "embedding","outputdim": 1},{"name": "sumPooling","type": "SumPooling","outputdim": 1,"inputlayers": ["wide","biinnersumcross","fclayer"]},{"name": "simplelosslayer","type": "SimpleLossLayer","lossfunc": "logloss","inputlayer": "sumPooling"}]
注: 在Angel中FCLayer在指定参数时采用了”折叠”方式. 更多例子请参考具体算法和Angel中的层
