 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- flume集成指南
- 方法一:基于推送的flume风格的方法
- 一般需求
- 配置flume
- 配置Spark Streaming应用程序
- 方法2:利用自定义sink的基于拉的方法
- 一般需求
- 配置flume
- 配置Spark Streaming应用程序
- 方法一:基于推送的flume风格的方法
flume集成指南
flume是一个分布式的、稳定的、有效的服务,它能够高效的收集、聚集以及移动大量的日志数据。flume的架构如下图所示。
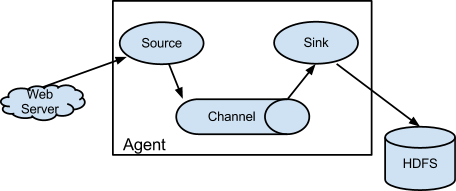
本节将介绍怎样配置flume以及Spark Streaming如何从flume中接收数据。主要有两种方法可用。
方法一:基于推送的flume风格的方法
flume被设计用来在flume agent间推送数据。在这个方法中,Spark Streaming本质上是建立一个receiver,这个receiver充当一个Avro代理,用于接收flume推送的数据。下面是配置的过程。
一般需求
在你的集群中,选择一台满足下面条件的机器:
- 当你的flume和Spark Streaming应用程序启动以后,必须有一个Spark worker运行在这台机器上面
- 可以配置flume推送数据到这台机器的某个端口
因为是推送模式,安排好receiver并且监听选中端口的流应用程序必须是开启的,以使flume能够发送数据。
配置flume
通过下面的配置文件配置flume agent,发送数据到一个Avro sink。
agent.sinks = avroSinkagent.sinks.avroSink.type = avroagent.sinks.avroSink.channel = memoryChannelagent.sinks.avroSink.hostname = <chosen machine's hostname>agent.sinks.avroSink.port = <chosen port on the machine>
查看flume文档了解更多的信息。
配置Spark Streaming应用程序
- 关联:在你的SBT或者Maven项目定义中,引用下面的组件到流应用程序中。
groupId = org.apache.sparkartifactId = spark-streaming-flume_2.10version = 1.1.1
- 编程:在应用程序代码中,引入
FlumeUtils创建输入DStream。
查看API文档和例子import org.apache.spark.streaming.flume._val flumeStream = FlumeUtils.createStream(streamingContext, [chosen machine's hostname], [chosen port])
注意,hostname必须和集群(Mesos,YARN或者Spark Standalone)的resource manager所使用的机器的hostname是同一个,这样就可以根据名称分配资源,在正确的机器上启动receiver。
- 部署:将
spark-streaming-flume_2.10和它的依赖(除了spark-core_2.10和spark-streaming_2.10)打包到应用程序jar包中。然后用spark-submit方法启动你的应用程序。
方法2:利用自定义sink的基于拉的方法
作为直接推送数据到Spark Streaming方法的替代方法,这个方法运行一个自定义的flume sink用于满足下面两点功能。
- flume推送数据到sink,该数据被缓存在sink中。
- Spark Streaming利用事务从sink中拉取数据。只有数据接收并且被Spark Streaming复制了之后,事务才算成功。这使这个方法比之前的方法具有更好的稳定性和容错性。然而,这个方法需要flume去
运行一个自定义sink。下面是配置的过程。
一般需求
选择一台机器在flume agent中运行自定义的sink,配置余下的flume管道(pipeline)发送数据到agent中。集群中的其它机器应该能够访问运行自定义sink的机器。
配置flume
在选定的机器上面配置flume需要以下两个步骤。
- Sink Jars:添加下面的jar文件到flume的classpath目录下面
- 自定义sink jar:通过下面的方式下载jar(或者这里)
groupId = org.apache.sparkartifactId = spark-streaming-flume-sink_2.10version = 1.1.1
- scala library jar:下载scala 2.10.4库,你能够通过下面的方式下载(或者这里)
groupId = org.scala-langartifactId = scala-libraryversion = 2.10.4
- 自定义sink jar:通过下面的方式下载jar(或者这里)
- 配置文件:通过下面的配置文件配置flume agent用于发送数据到Avro sink。
agent.sinks = sparkagent.sinks.spark.type = org.apache.spark.streaming.flume.sink.SparkSinkagent.sinks.spark.hostname = <hostname of the local machine>agent.sinks.spark.port = <port to listen on for connection from Spark>agent.sinks.spark.channel = memoryChannel
要确保配置的逆流flume管道(upstream Flume pipeline)运行这个sink发送数据到flume代理。
配置Spark Streaming应用程序
- 关联:在你的SBT或者Maven项目定义中,引入
spark-streaming-flume_2.10组件 - 编程:在应用程序代码中,引入
FlumeUtils创建输入DStream。
import org.apache.spark.streaming.flume._val flumeStream = FlumeUtils.createPollingStream(streamingContext, [sink machine hostname], [sink port])
可以查看用例FlumePollingEventCount
注意,每个输入DStream都可以配置为从多个sink接收数据。
- 部署:将
spark-streaming-flume_2.10和它的依赖(除了spark-core_2.10和spark-streaming_2.10)打包到应用程序的jar包中。然后用spark-submit方法启动你的应用程序。
