- 监控的内容
- 监控效果图
- 1. 模板变量
- 2. 全局概览
- 3. CPU Usage 信息
- 4. 系统 load 值与进程
- 5. 内存用量
- 6. kernel 信息
- 7. CPU 的状态
- 8. 网络相关
- 9. 交换分区状态
- 10. 磁盘用量
- 快速开始
- 第一步:下载&启动 logkit
- 第二步:配置 metric 采集收集器
- 第三步: 配置 Grafana 数据源
- 【可选】配置LogDB 数据源
- 第四步: 导入 Grafana dashboard 配置文件
- 配置 Grafana 告警
- 配置 Grafana 告警
系统运维监控 - 使用 Pandora 快速构建服务器性能监控系统
服务器监控是每个互联网厂商都重视并且想要尽可能做好的事情,从数据收集、数据处理、数据可视化最终再到实时监控告警,这一系列复杂的流程可能耗费企业大量的人力和时间,以至于某些时候因为其复杂性高无法达到预期的监控效果。而当事故发生时才发现,由于监控体系的不完善造成了很多不必要的损失, 让我们追悔莫及。
为了解决企业的此类烦恼,七牛云推出了快速构建服务器性能监控报警的解决方案。七牛云开源的日志/信息采集工具 logkit 配合七牛云 Pandora 大数据工作流引擎和时序数据库服务,可以方便地对大量服务器的海量性能指标数据进行全方位监控。而整个部署和使用的流程,您完整体验的时间仅需15分钟。
监控的内容
logkit 目前收集的机器性能指标主要包括十大模块, 上百个指标
system模块: 监控load1、load5、load15、用户数、cpu 核数以及系统启动时间等.processes模块: 监控处于各种状态的进程数量, 比如运行中/暂停/可中断/空闲/挂起等状态的进程数量等等.netstat: 监控处于各种状态的网络连接数, 比如syn send/syn recv等状态的网络连接数.net: 监控网络设备的状态,比如收发包的数量、收发包的字节数等.mem: 监控内存的实时状态.swap: 监控 swap 分区的状态,比如换入、换出、使用率、空闲大小等.cpu: 监控 CPU 的实时状态,包括cpu 用量,中断时间占比等.kernel: 监控内核中断次数、上下文切换次数、fork 的进程数等.disk: 监控磁盘的使用情况, 包括磁盘用量、inode 使用情况等.diskio: 监控磁盘读写状态, 包括读写次数、总用时等.
各项指标的详细介绍请参考 logkit 系统信息采集模块介绍和配置
监控效果图
部署完成后,您可以直接载入我们为您构建的监控模板,最终看到的效果图如下。
1. 模板变量
模板变量可以起到过滤数据的作用, 比如通过hostname这个模板变量可以具体查看某台特定的服务器上的metric信息,这样即使有数十上百台机器您也可以轻松管理。同样的,对于某台机器的一些具体的资源,如磁盘、CPU、网卡等等,也有相应的模板变量可以选择。
2. 全局概览
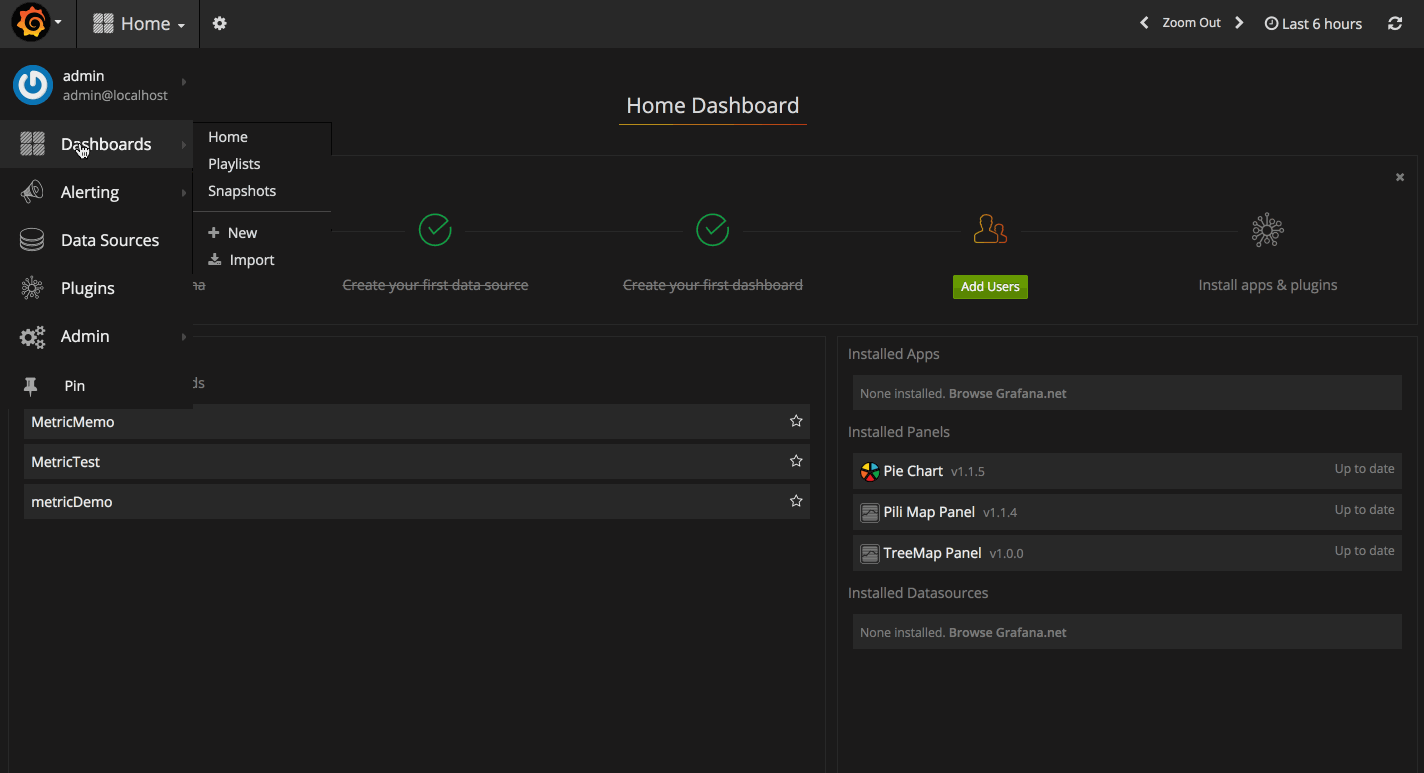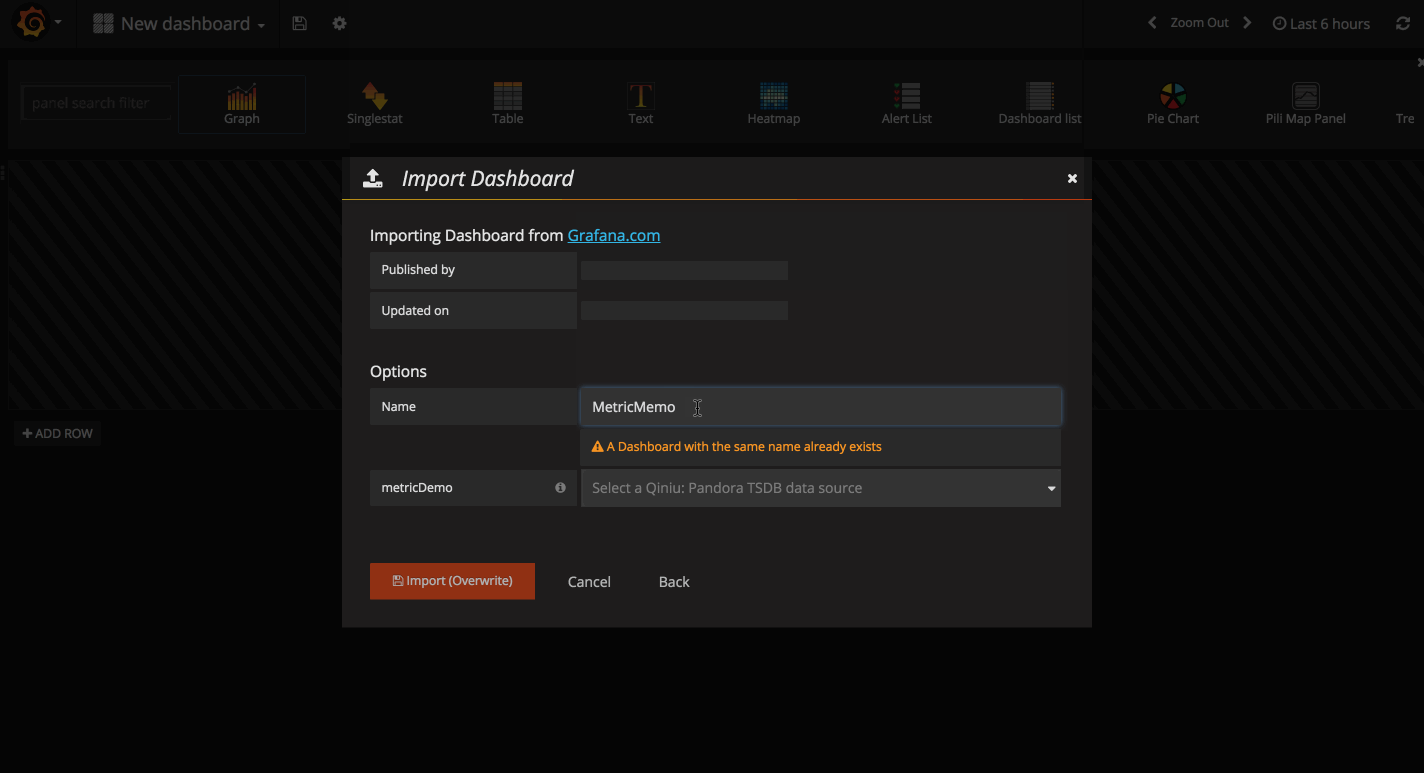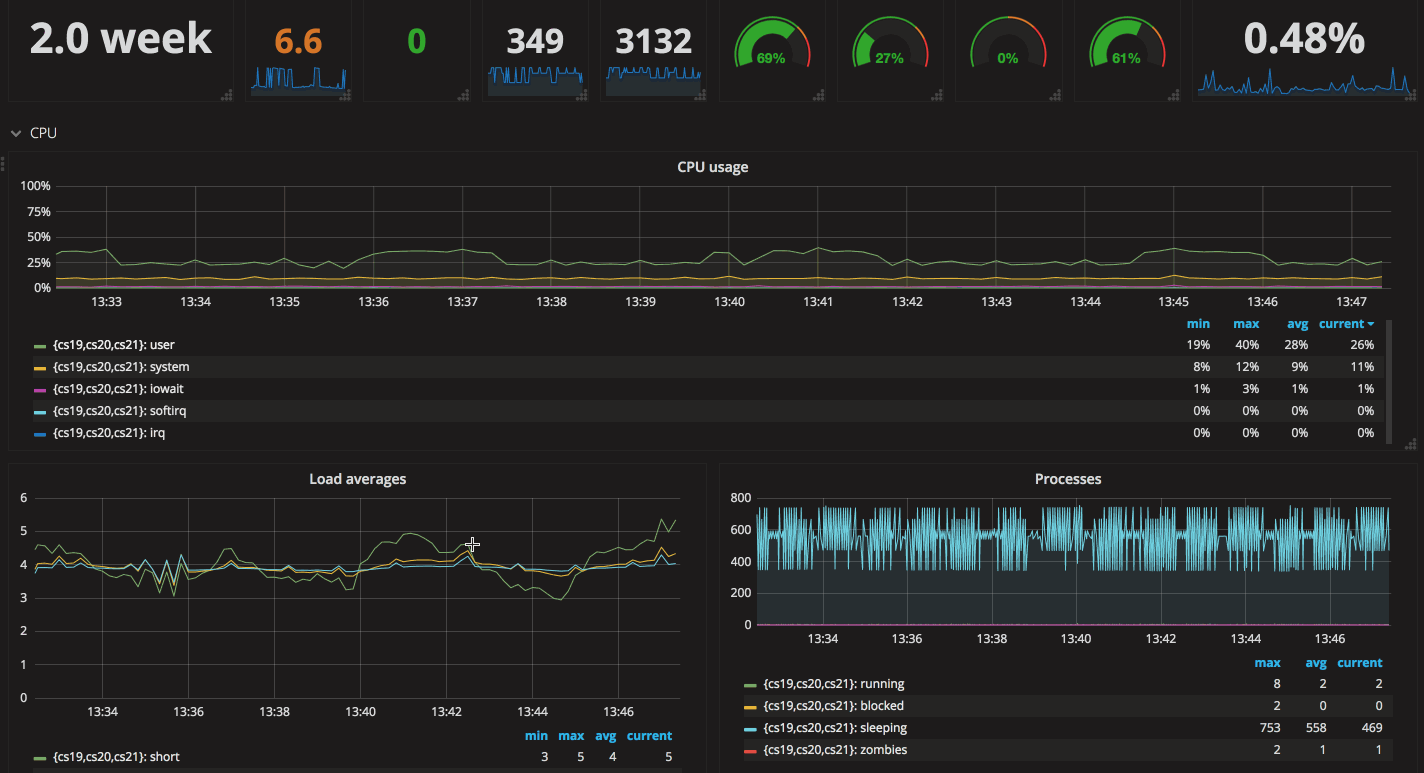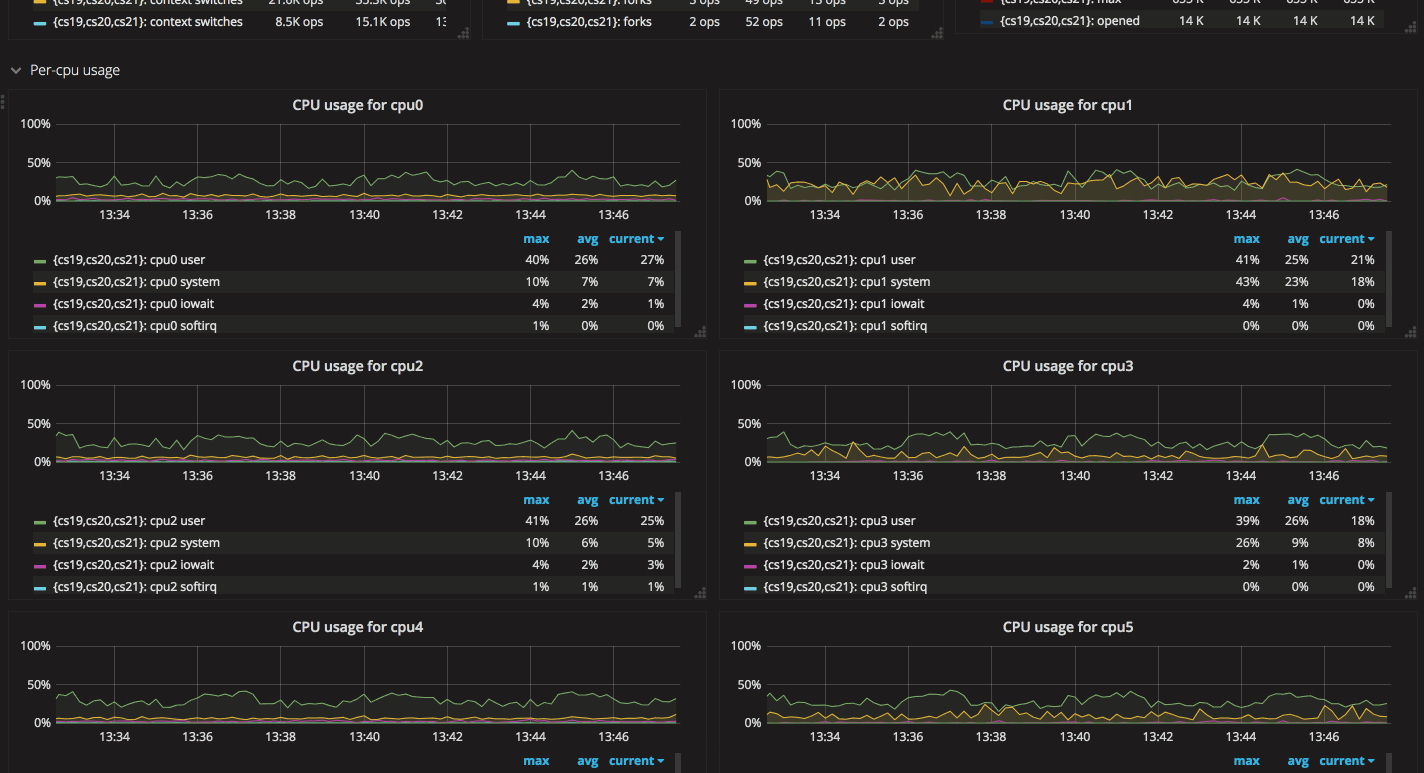
全局信息概览可以看到服务器的一些基本信息,比如系统 load 值、内存使用率、磁盘使用率、网络带宽等。以最直观的方式全局把控整个系统的运行状态,方便在基础资源不够时及时发现、及时处理。
3. CPU Usage 信息
CPU Usage 顾名思义,就是指 CPU 的使用率,通过这幅图可以看到系统中 user、system 等对于系统 CPU 资源的占用情况。当 CPU 使用率较高且整体运行平稳时,说明您的业务非常健康;若 CPU 的用量曲线波动较大,那就说明服务有可以优化的地方,或者可以添加报警,在业务高峰时及时添加资源。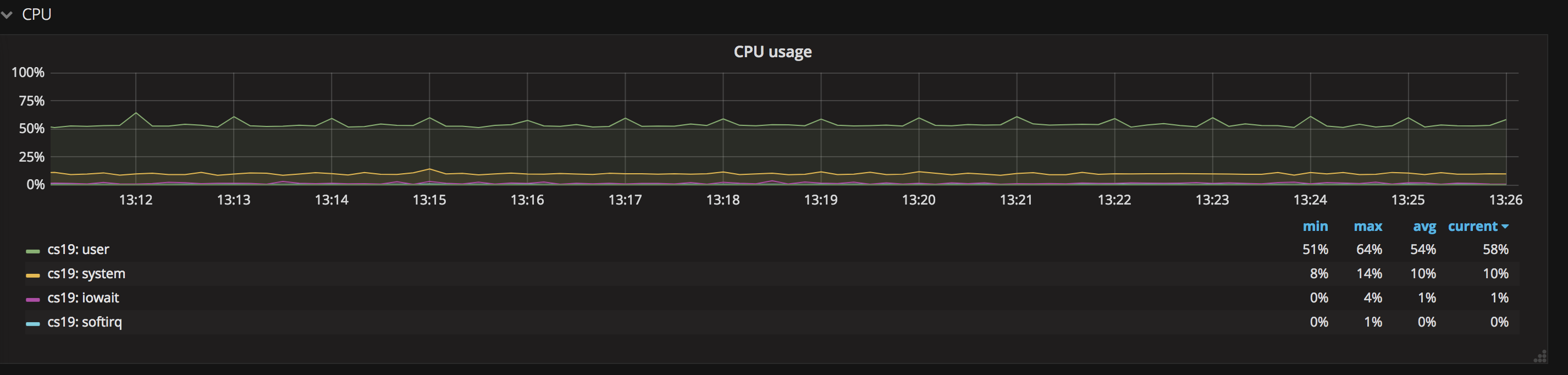
4. 系统 load 值与进程
在这张图中你可以看到不同的统计时间段中系统的负载情况,可以根据负载大小设置告警阈值。同时也可以看到对应的进程数量, 如运行的进程数、在休眠中的进程数,并且可以看到值得关注的一些异常进程,如僵尸进程(zombies)以及被阻塞的进程(blocked)。当存在僵尸进程时说明存在服务异常,需要及时关注并处理。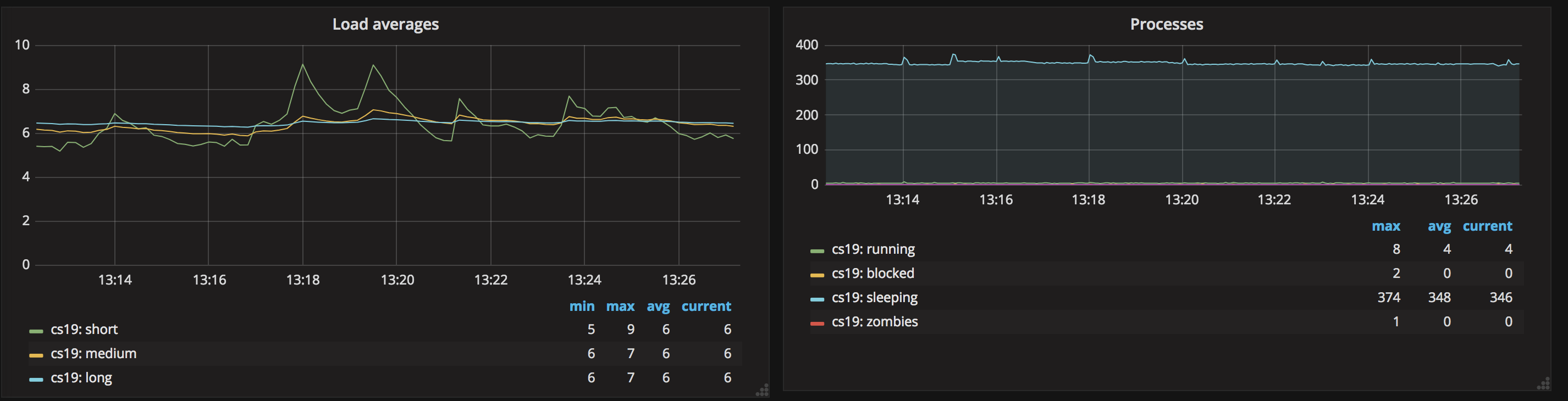
5. 内存用量
通过这张图可以看到总内存(total)、已使用内存(used)、空闲内存(free)等信息, 同理, 也可以针对这些信息设置告警,及时发现系统性能短板。另一方面要注意,当系统free的内存少或接近零,而cache部分的内存多时,说明这部分业务对内存缓存较为依赖,虽然服务仍然可以正常运行,但此时极有可能程序没法最大限度利用内存缓存, 导致性能出现了问题。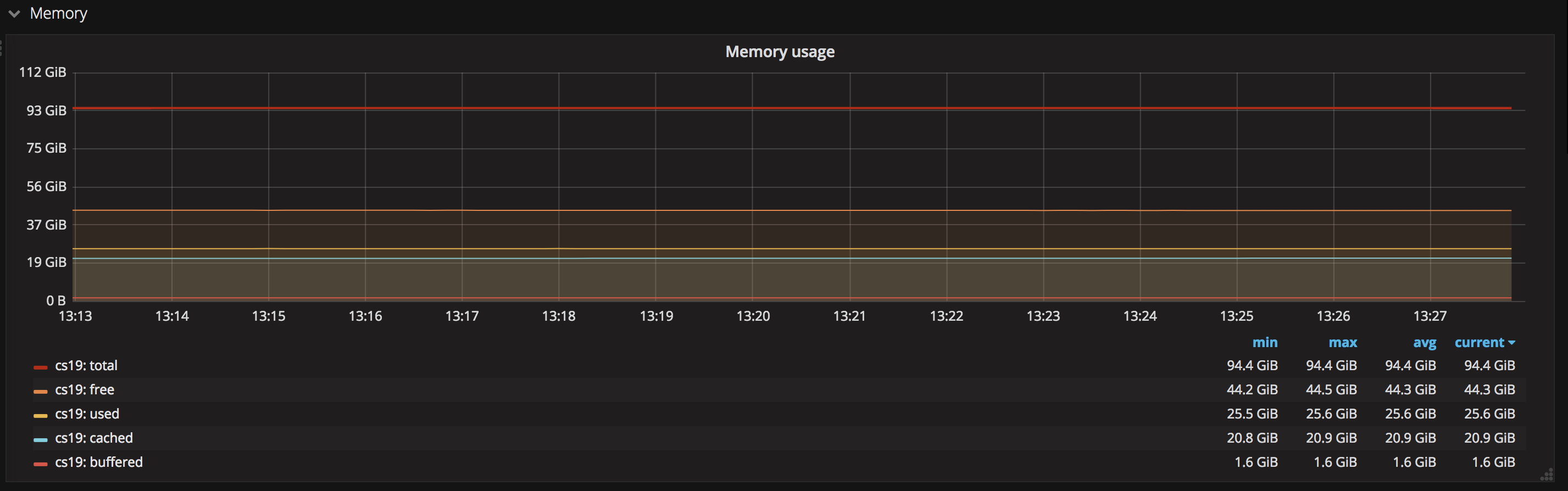
6. kernel 信息
kernel 基本信息中可以看到内核的上下文切换(context switch)、 fork 的进程数(forks)、 已打开(opened)/最大(max)句柄数等信息。通常情况下服务器打开的句柄数都有一个上限,超过了这个限制服务就会出现问题,而服务器的高并发访问极有可能导致打开的句柄数过多,实时监控句柄数有助于查看服务运行状况。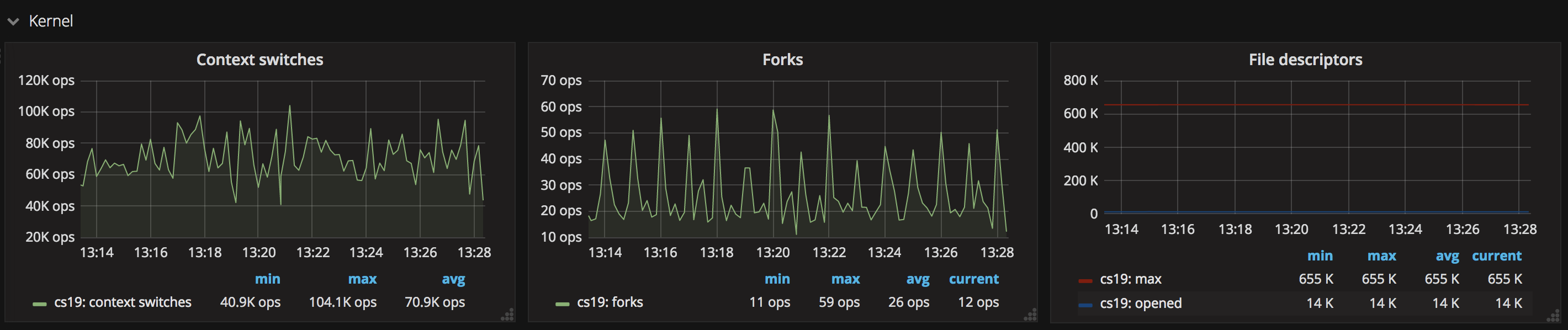
7. CPU 的状态
在这张图中可以看到服务器中各个的CPU的状态,是对于 CPU Usage 的详细拓展。CPU 是一种弹性资源,即使使用量达到 100% 也不会出现直接的服务崩溃,但是极有可能导致服务响应变得极慢,密切关注 CPU 用量,并对于 CPU 设置报警监控也是运维必不可少的一环。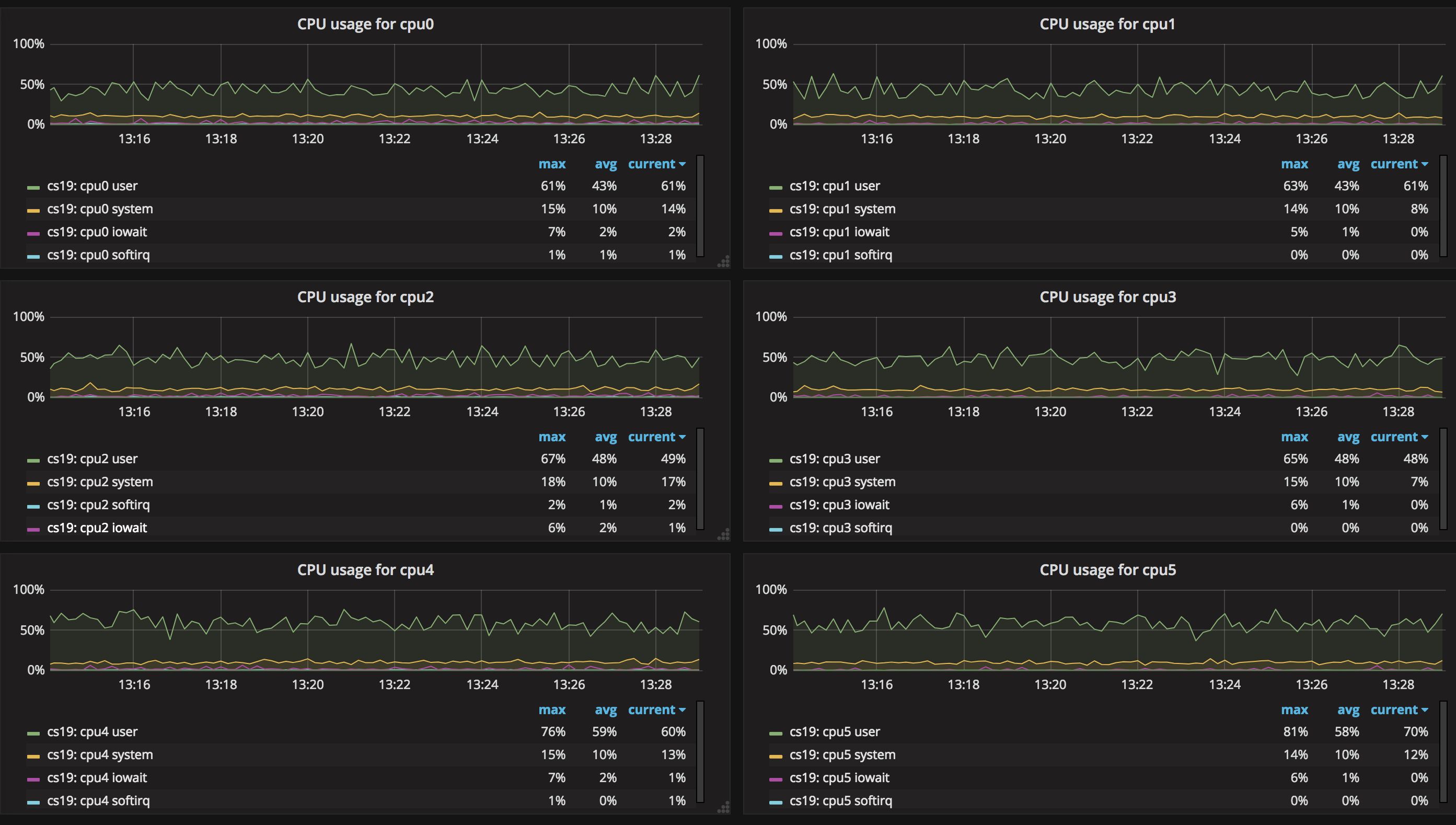
8. 网络相关
- TCP
这张图展示了系统中处于各个状态的 TCP 连接数量,比如SYN SENT、FIN WAIT 等, 利用这些数据可以及时发现请求的健康状态,常见的如出现大量的FIN WAIT、CLOST WAIT等状态的连接,说明出现了很多慢请求或连接有问题,需要排查,通常这一类指标可以结合打开文件句柄数一同查看。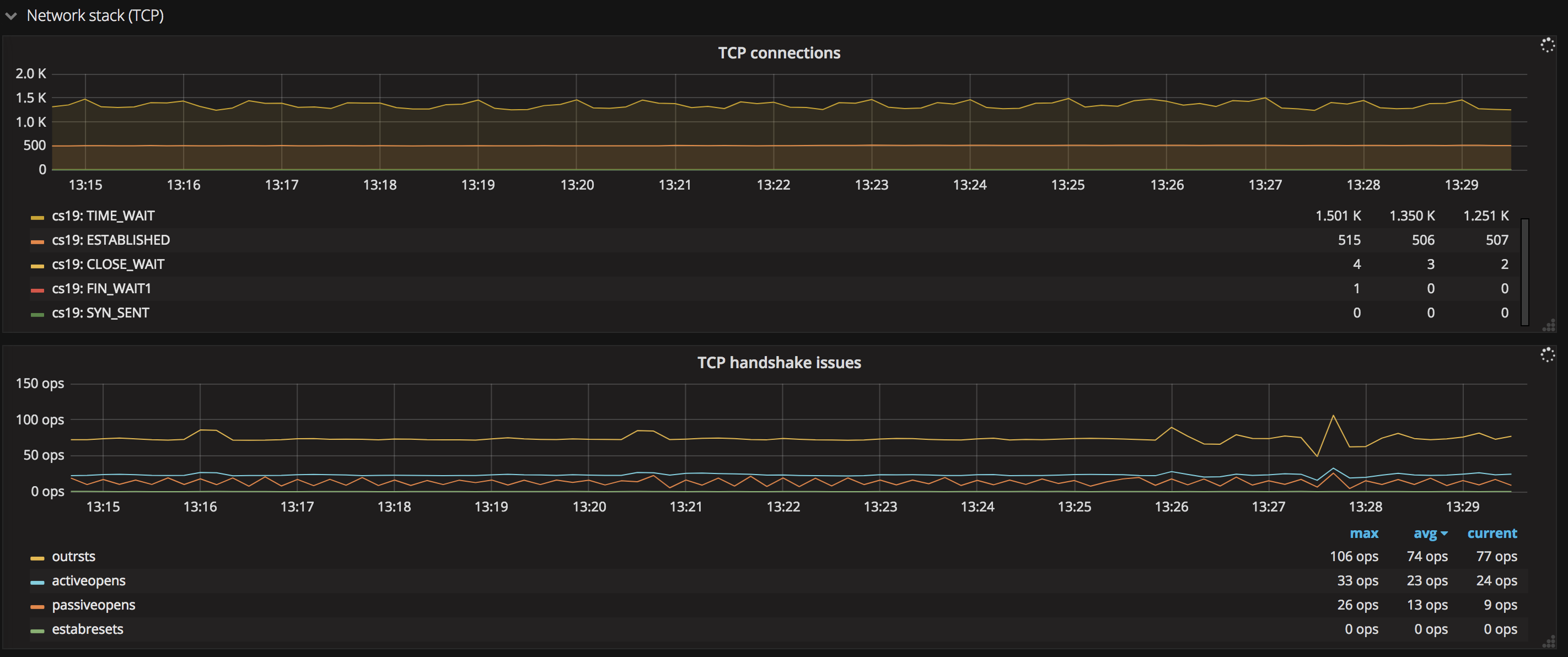
- ICMP、IPV4
这张图中可以看到 icmp、ipv4 等网络协议的收发状态。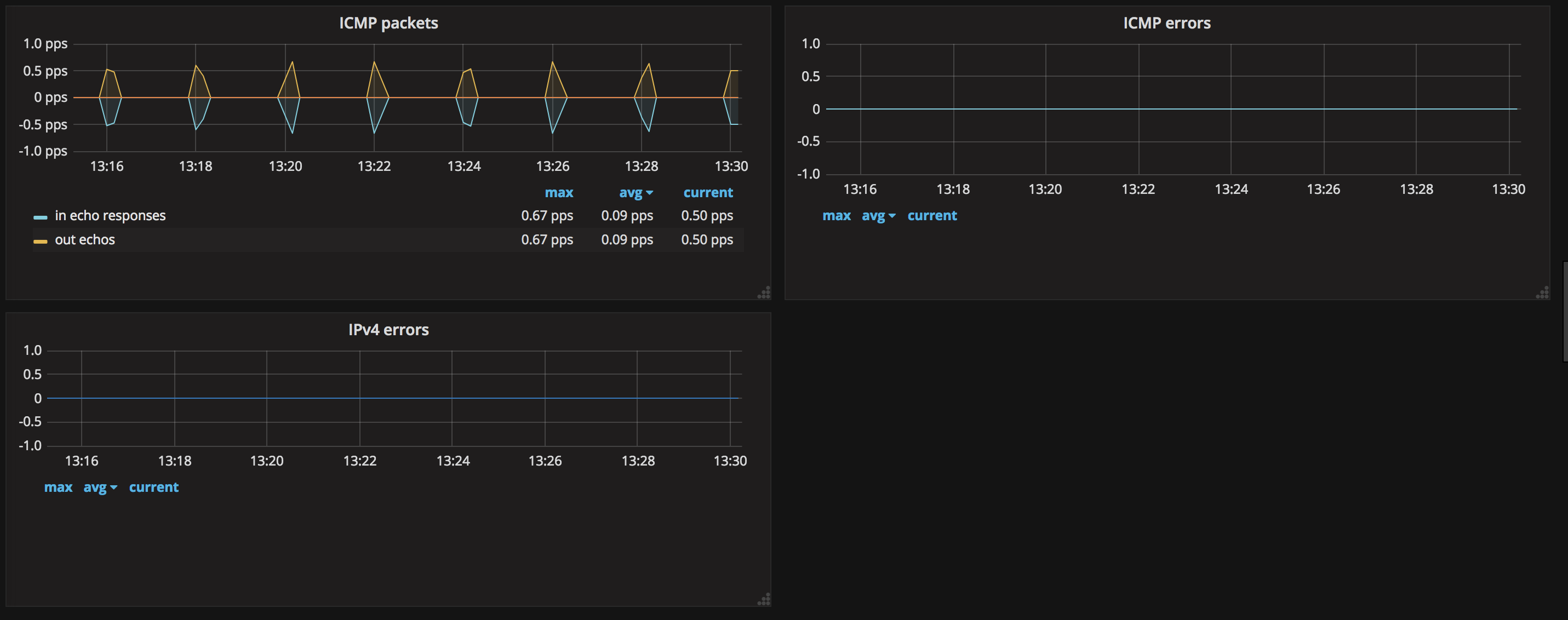
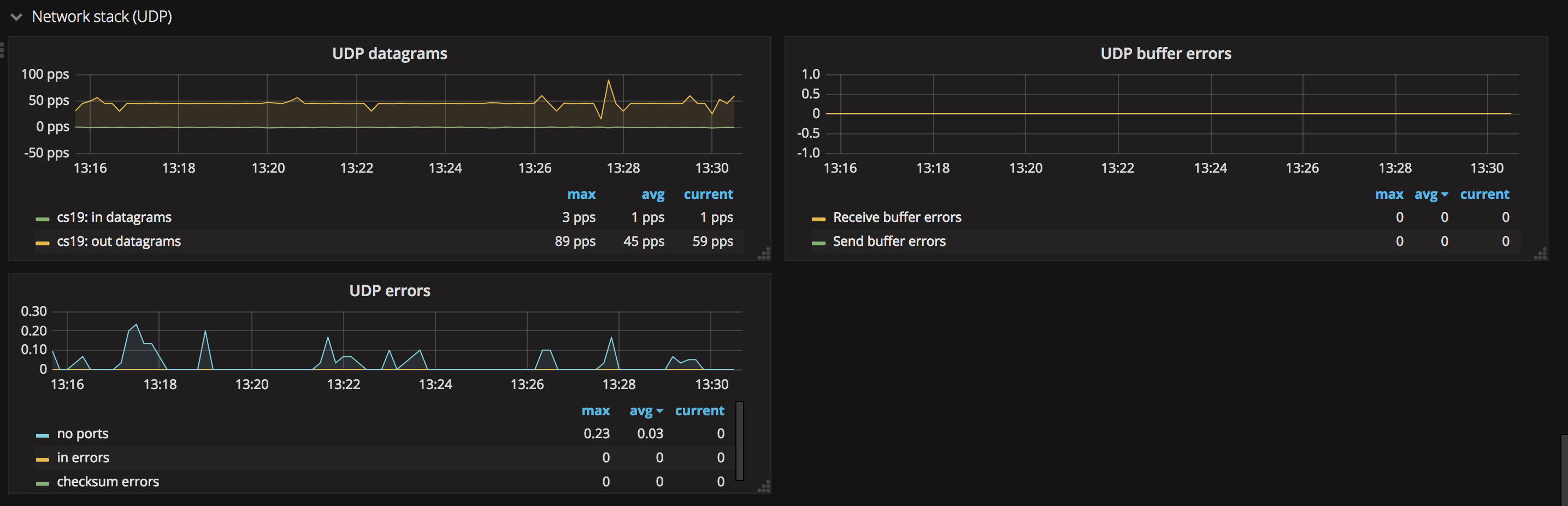
- UDP
这张图中可以看到 udp 数据报 以及 udp 错误数目等,如错误数过多,表示网络状况不佳。
- 各个网卡的状态
网卡状态展示了包括网卡收发数据的速度(Network Usage)、收发包的速度(Network Packets)、丢包率(Network drops)以及出错频率(Network errors)等信息。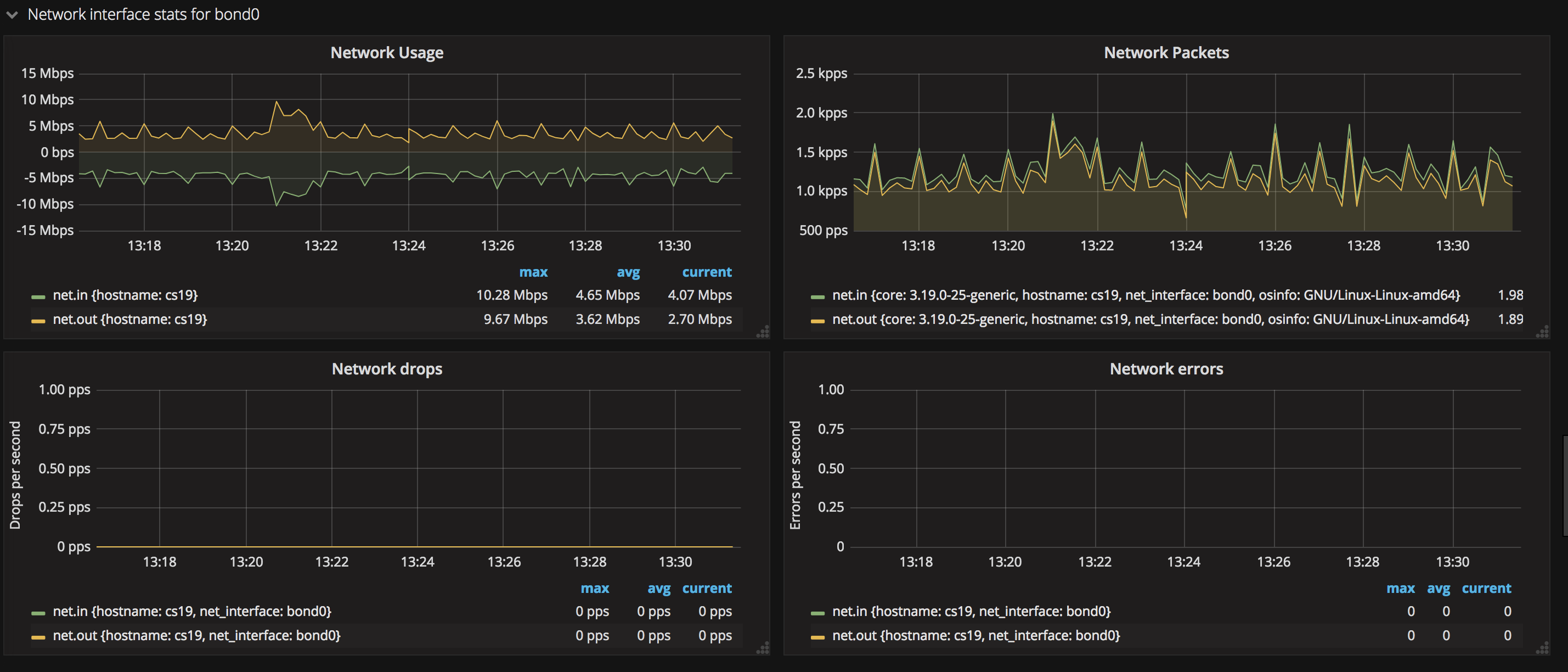
9. 交换分区状态
这张图展示了交换分区的换入换出状态、交换分区的使用情况等。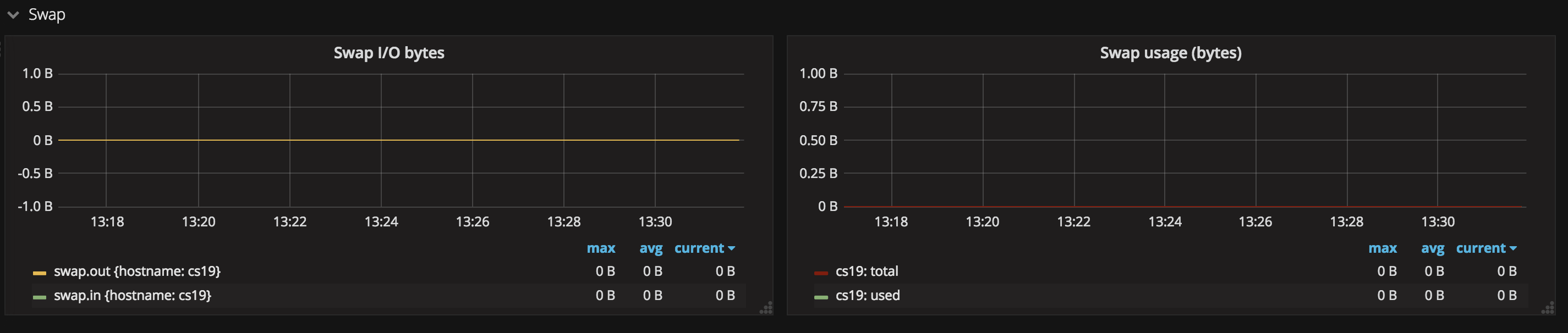
10. 磁盘用量
磁盘的重要性毋庸置疑,磁盘爆满可能会对服务产生毁灭性打击,无疑也是需要监控的重点。
- 磁盘 IO
这张图给出了当前各个磁盘的 IO 信息,包括磁盘请求频率(Disk IO requests)、读写速度(Disk IO bytes)以及读写时间(Disk IO time)等,当磁盘 IO 过高时,也有可能存在性能问题,需要关注。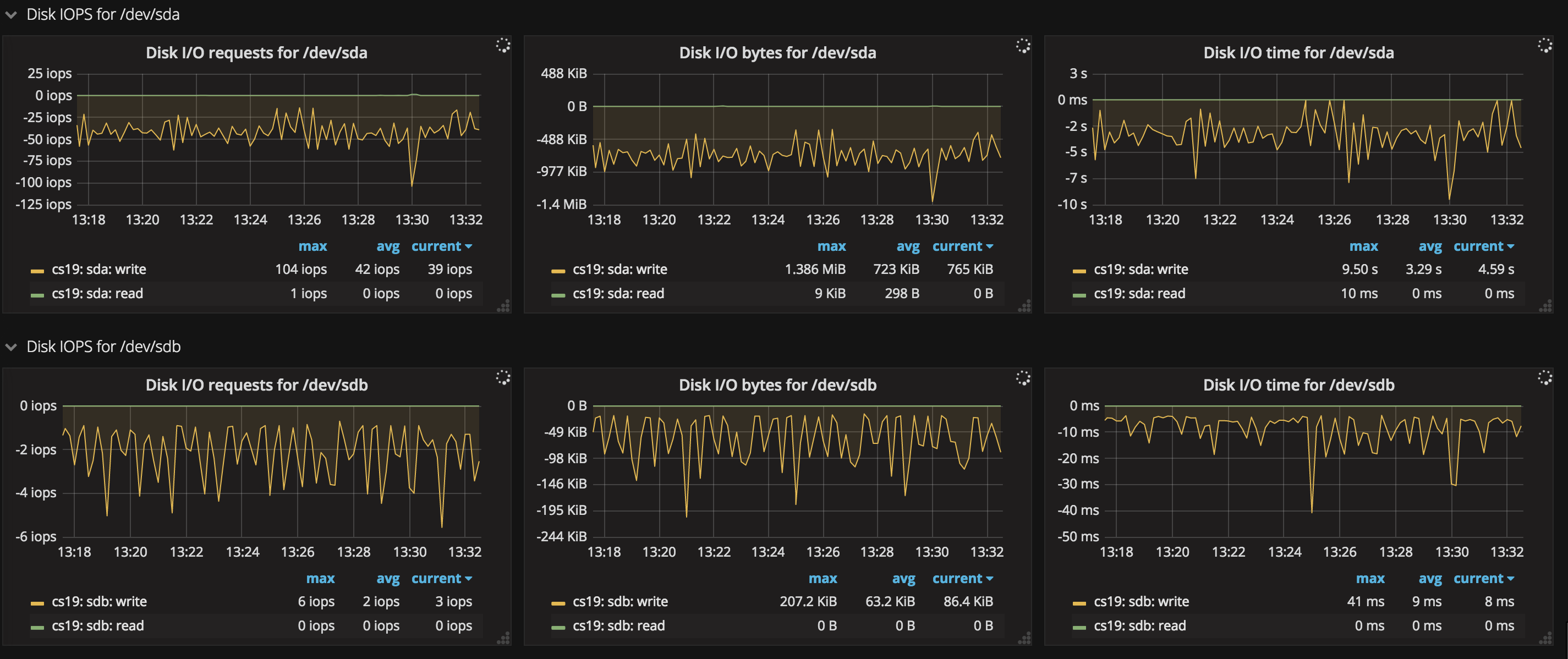
- 磁盘使用情况
这张图中可以看到磁盘总空间(total)与已使用空间(used), 实时展现磁盘使用情况,并且可以设置告警机制,当磁盘的剩余空间少于某个阈值时及时告警。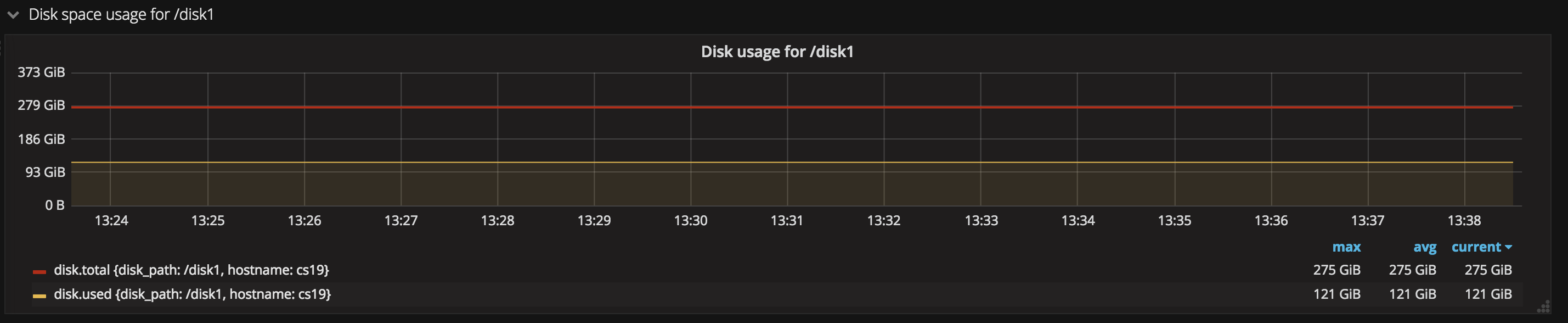
快速开始
下面就 Pandora 提供的组件来搭建一个运维监控应用,搭建这个应用只需要四步。
!> 注意,为了顺利使用 Pandora 的各项服务,第一,需要一个已经实名认证的七牛账户;第二,申请开通 Pandora 的使用权限;
第一步:下载&启动 logkit
从 logkit下载页面 下载对应操作系统的 logkit 应用程序。logkit 的详细配置可以参考 logkit Wiki, 当然如果没有特殊需求,只需要使用默认的配置即可。
启动 logkit,输入以下命令
./logkit -f logkit.conf
第二步:配置 metric 采集收集器
借助 logkit 的可视化配置界面,可以很方便的配置需要采集的 metric 信息,在浏览器中输入配置的 url 访问 logkit 管理中心(默认为 http://127.0.0.1:3000)。
- 打开
logkit配置助手后,点击增加系统信息采集收集器按钮,进入编辑收集器页面.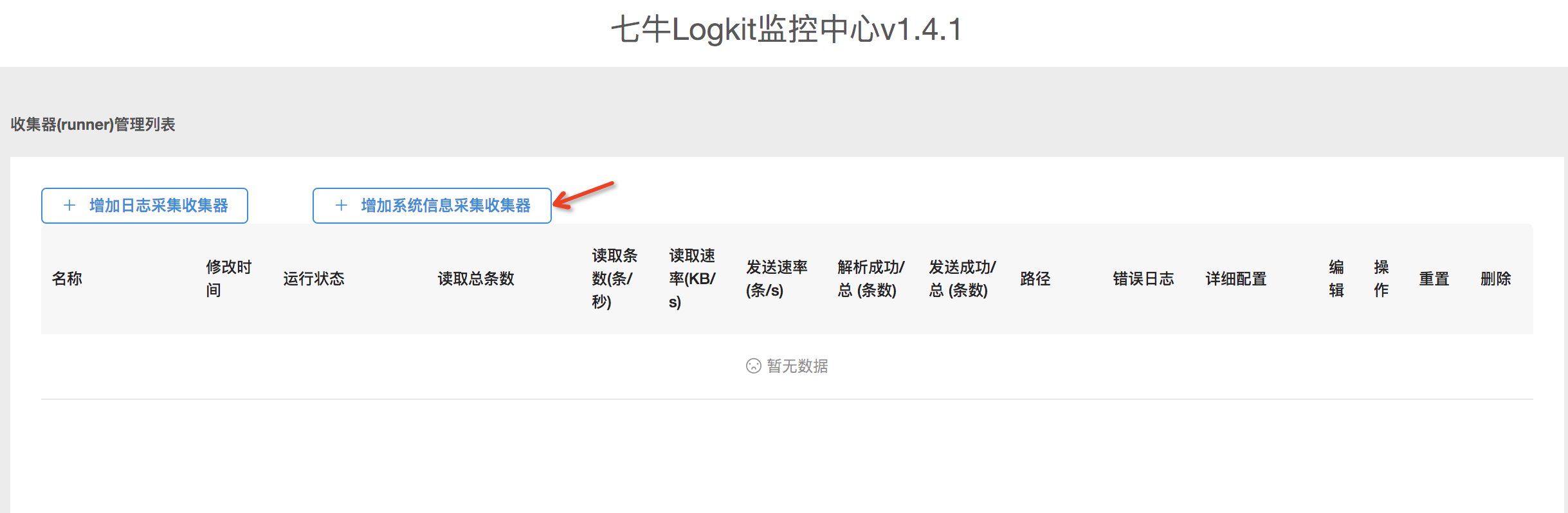
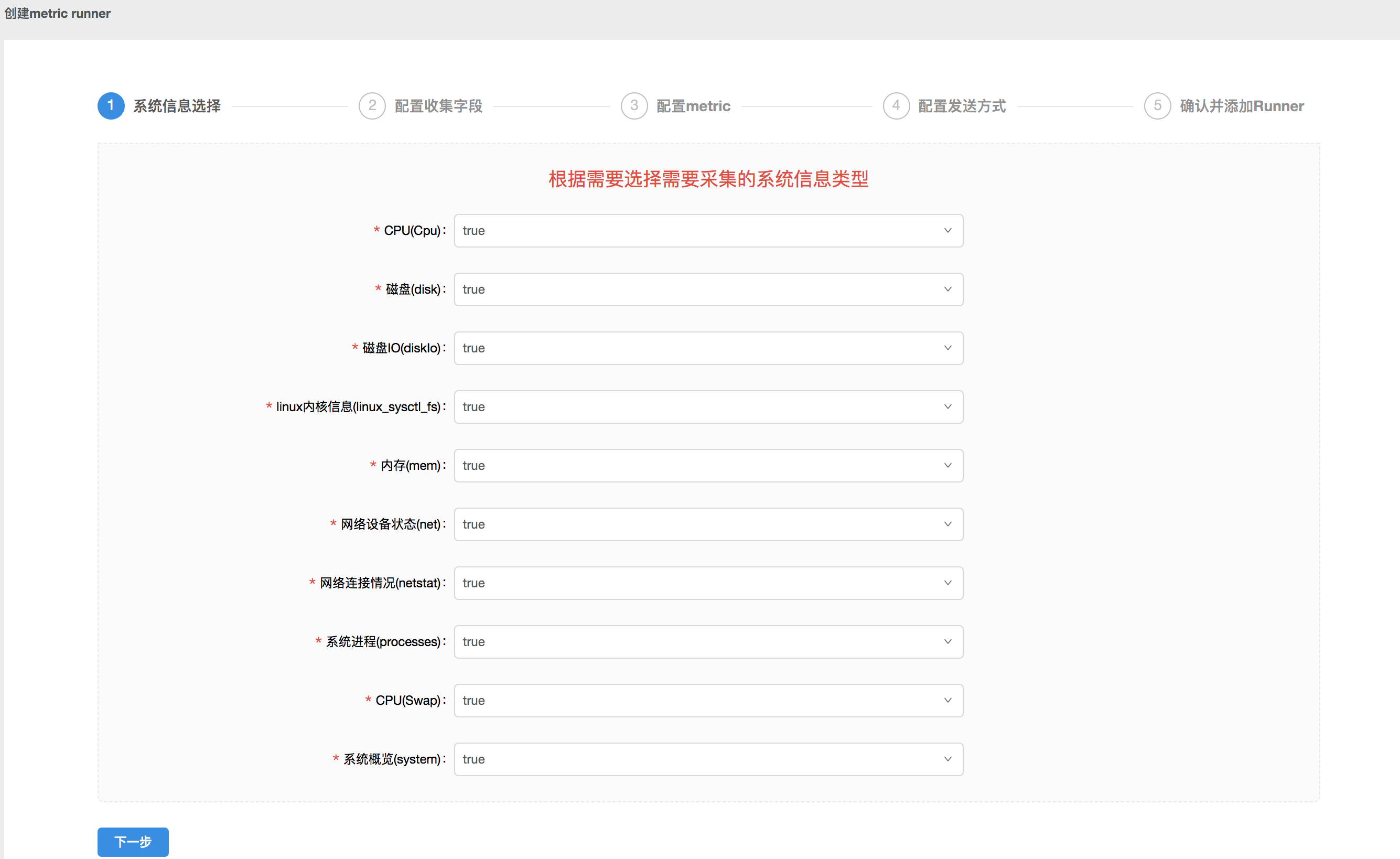
- 首先选择要收集的 Metric 信息类型,默认收集全部信息,点击下拉框可以选择不再收集。
- 然后选择每个想要收集的
Metric的字段,通过“全选/全不选“按钮可以快速选中/取消选中所有的字段。注意:请至少为每个Metric信息选择一个字段;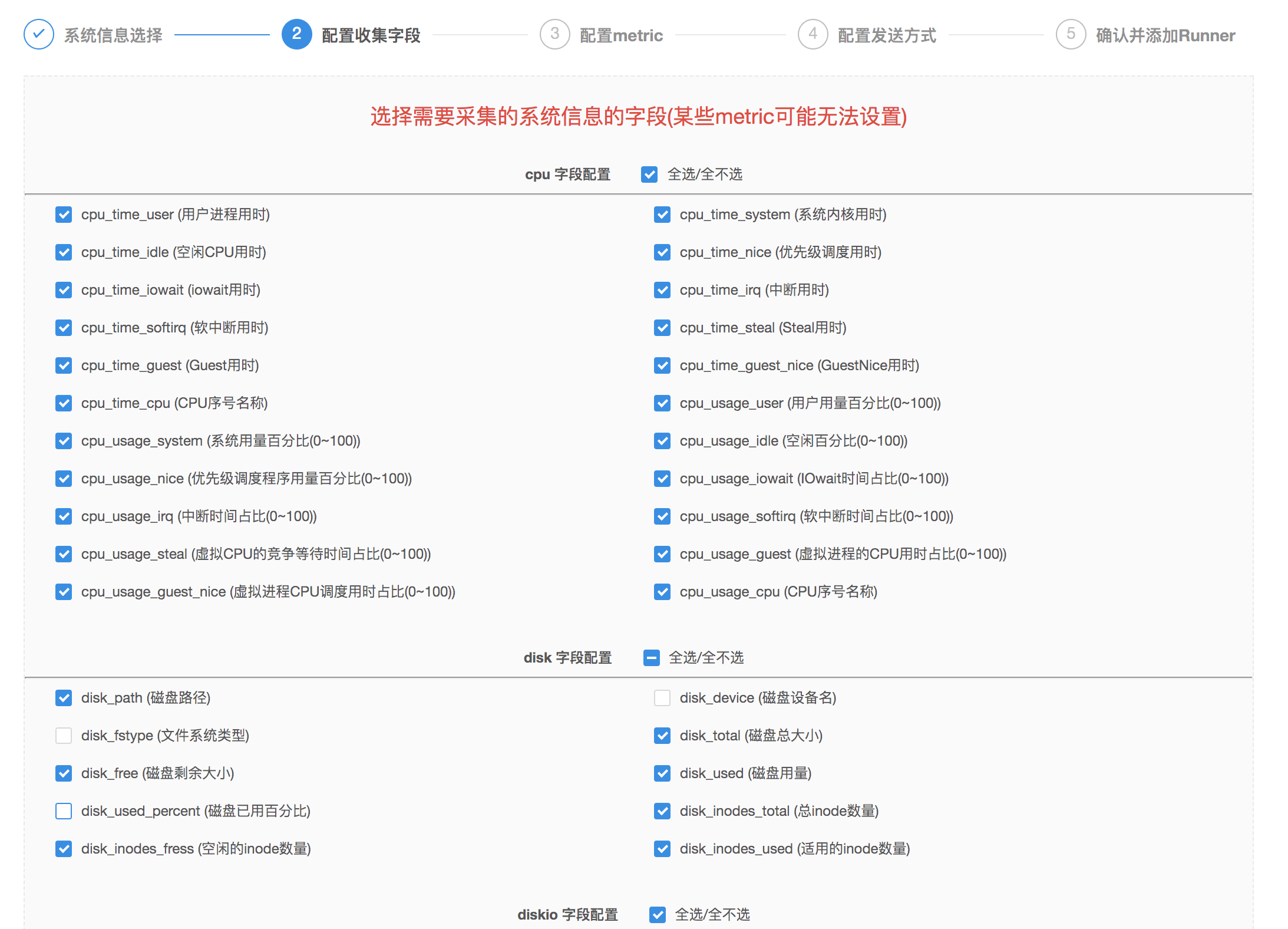
- 然后填写相关
Metric的配置信息,注意:有些Metric没有可以填写的配置,所以没有显示;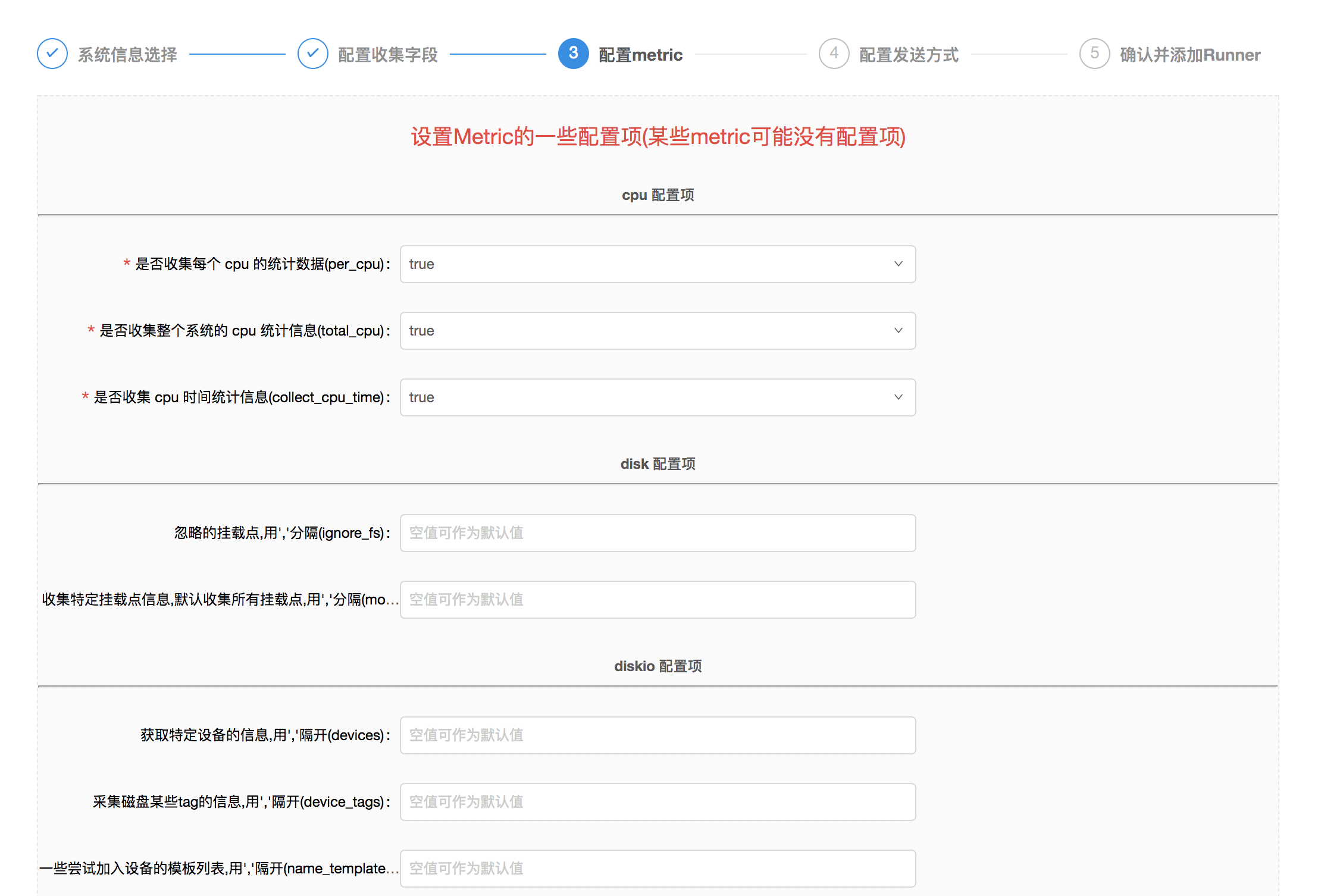
- 填写发送的目的地,将数据发往
pandora平台时,选择pandora sender, 填入自己pandora账号的ak/sk, 填入reponame,如果没有特殊需求,其他的选项可以使用默认值, 详细的sender信息,可以参考Senders Wiki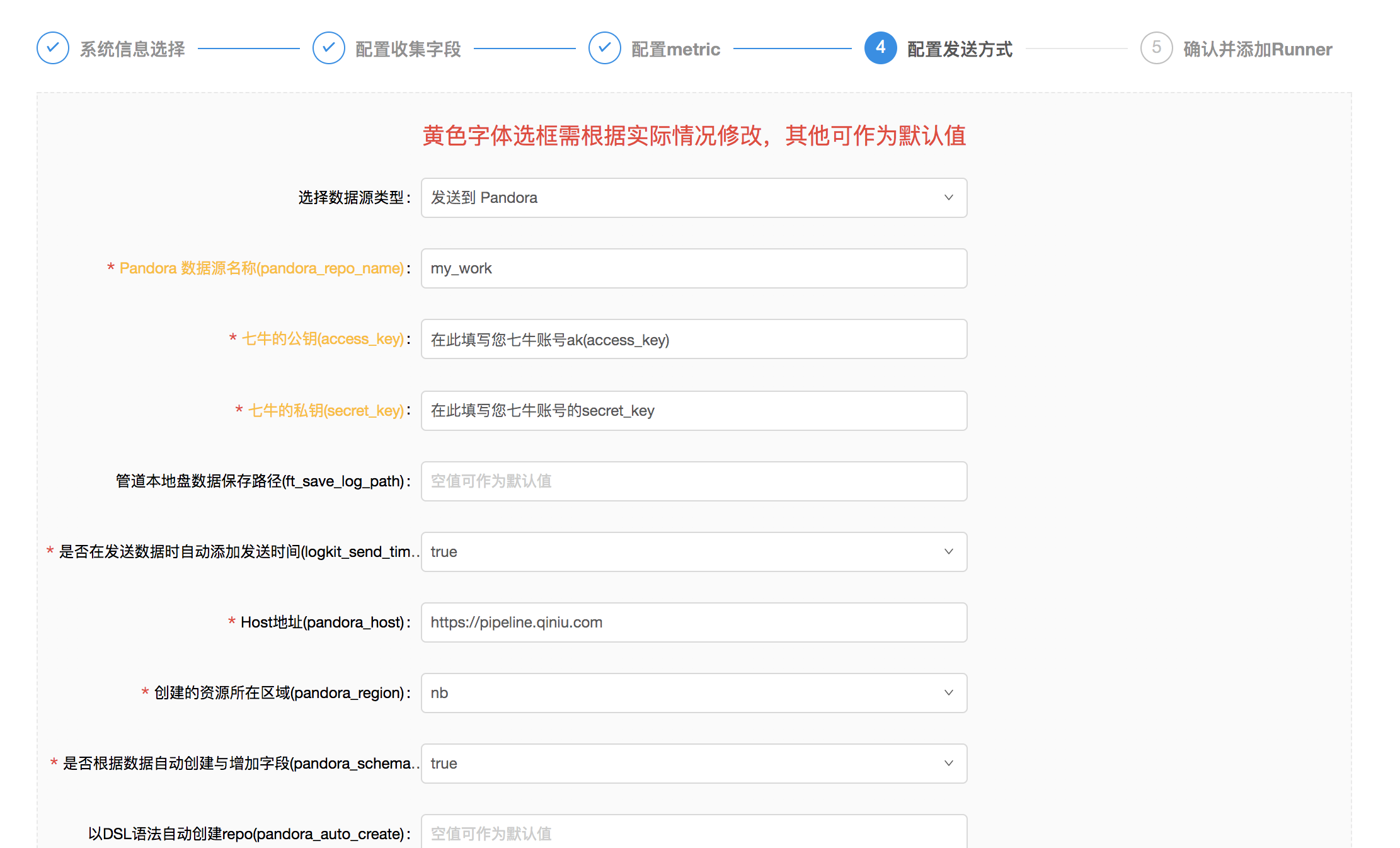
- 最后可以浏览一下配置文件的内容,避免之前有忽略的错误,同时可以自定义配置 metric 信息收集的频率,默认是
3s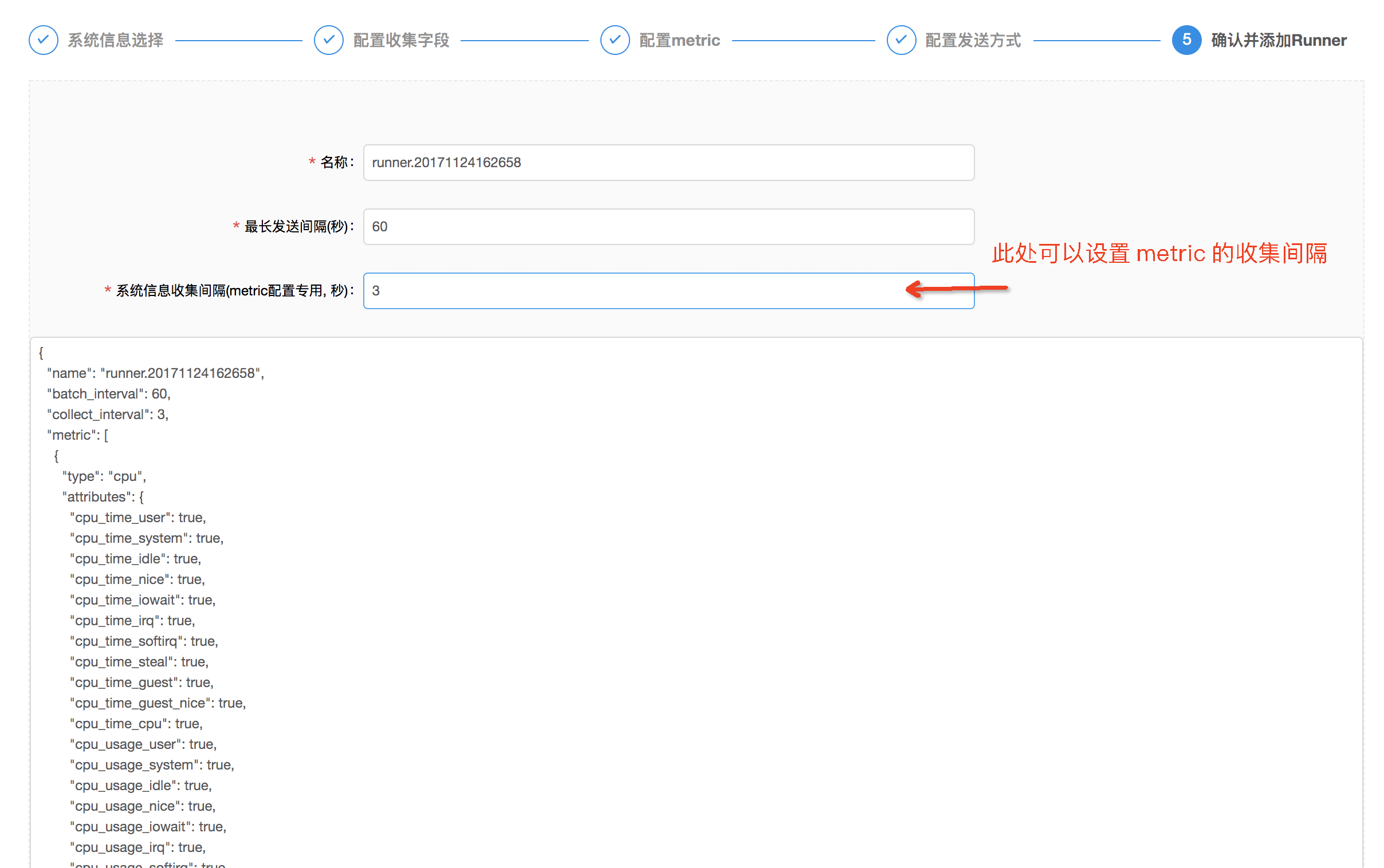
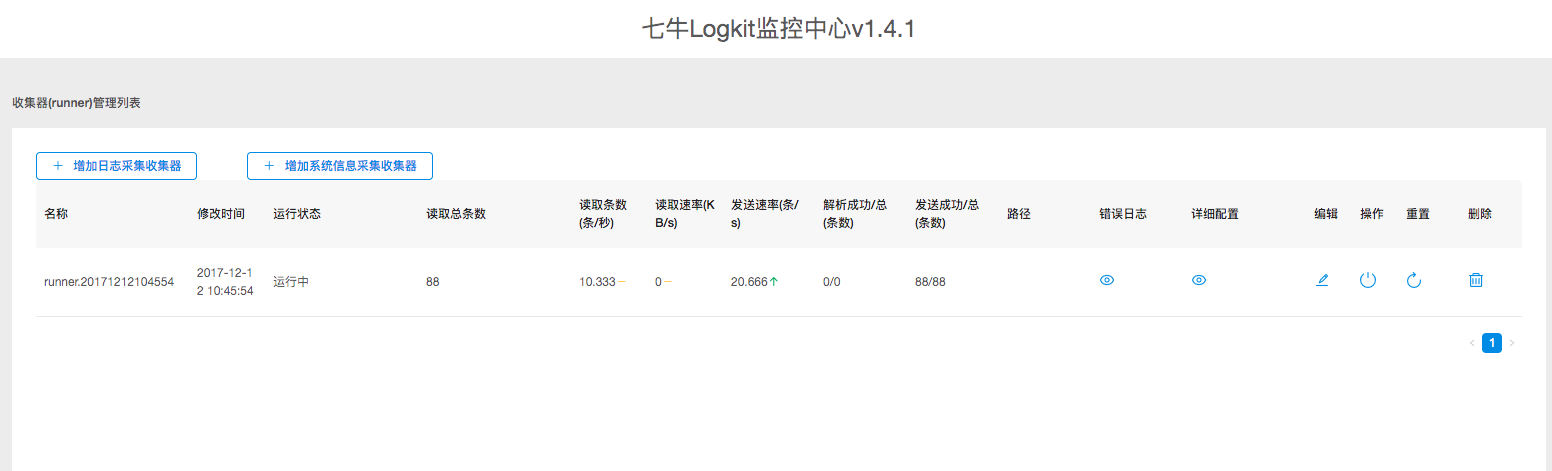
- 点击“确认并提交“后,一条收集 metric 信息的 runner 就创建成功了。
第三步: 配置 Grafana 数据源
在七牛应用市场打开 Grafana 应用,然后按照以下步骤配置:
创建应用
1.首先登陆七牛 portal 的应用平台 找到 Grafana
2.点击立即部署按钮开始创建 Grafana 应用
输入您的 app 名和应用别名,选择部署区域(注意!目前 TSDB 的数据在华东,所以 Grafana 只可部署在华东区域),点击确定创建
应用名称:账号内唯一应用名称,且只能满足以下条件:(1. 只能包含字母、数字和减号,首尾字符只能为字母或数字。 2. 字符长度不能超过 30)
应用别名:供显示使用的标题名。
3.等待 app 启动后,输入密码(密码长度必须>=6),点击 确认配置
注意,因为 Grafana App 具有公网域名,所以建议设置一个高强度的密码(此密码在进入 Grafana App 后可以修改)。

4.访问 Grafana 进入 Grafana 页面
注意,该 Grafana App 是暴露在公网上的,可收藏地址用于后续访问。

配置 TSDB 数据源
在 Grafana 中使用 Pandora TSDB 之前,我们需要先添加数据源。
登录 Grafana,点击菜单中的 Data Sources

点击 Add data source 按钮

在
Name填入数据源的名字, Type 选择 Pandora TSDB
填入相应参数,点击添加按钮即可
如果在上面metric收集器的sender配置中没有额外配置pandora_tsdb_reponame的话,此处的Name填写上面配置的pandora_repo_name注意: url 必须填入 http://localhost:8999

【可选】配置LogDB 数据源
如果您使用的是LogDB,即在logkit端默认导出到日志分析仓库,可以参考这里,进行LogDB数据源配置,同样可以进行服务器性能监控。
第四步: 导入 Grafana dashboard 配置文件
下载 Grafana dashboard 配置文件
下载配置文件模板 https://pandora-dl.qiniu.com/MetricMemo.json
如果您使用的是LogDB,可以参考如下链接
下载LogDB 配置文件模板 https://pandora-kibana.qiniu.com/MetricsLogdb-1514293429865.json
将下载的 dashboard 导入 Grafana
至此,您就可以看到一张酷炫的可视化运维监控图啦,当然没有报警的监控是不完整的,下面我们配置一下监控的告警。
配置 Grafana 告警
就在Grafana上,我们为您提供了完善的报警功能。
设置 Grafana 报警的 Channel
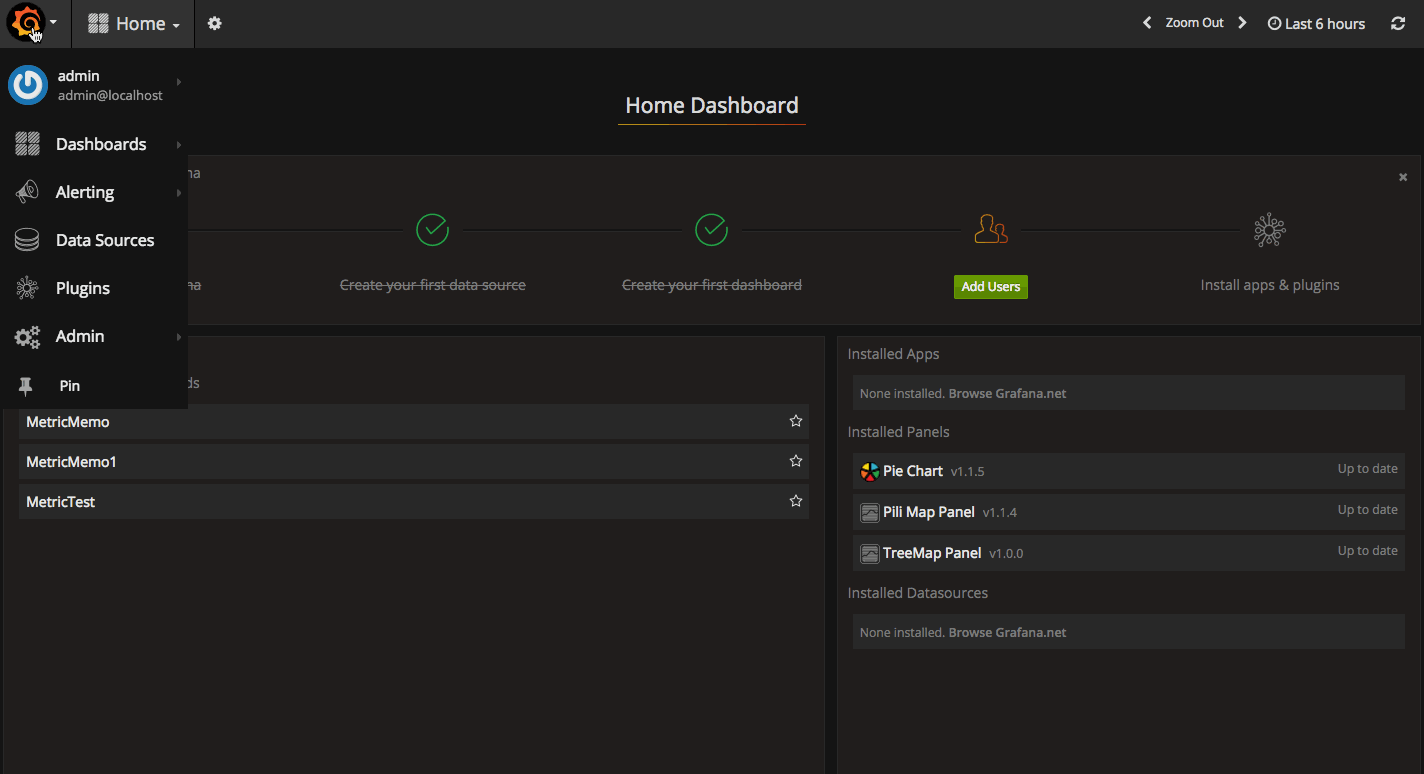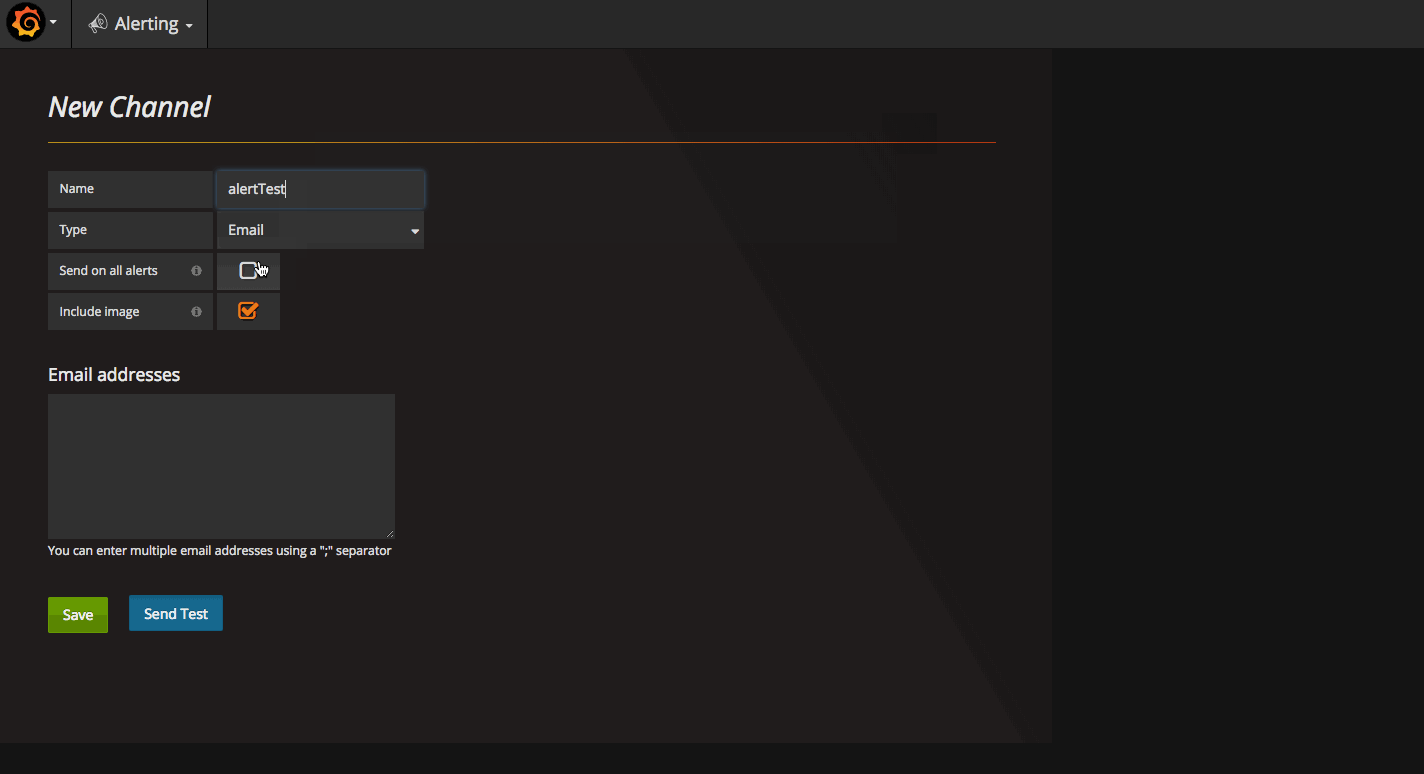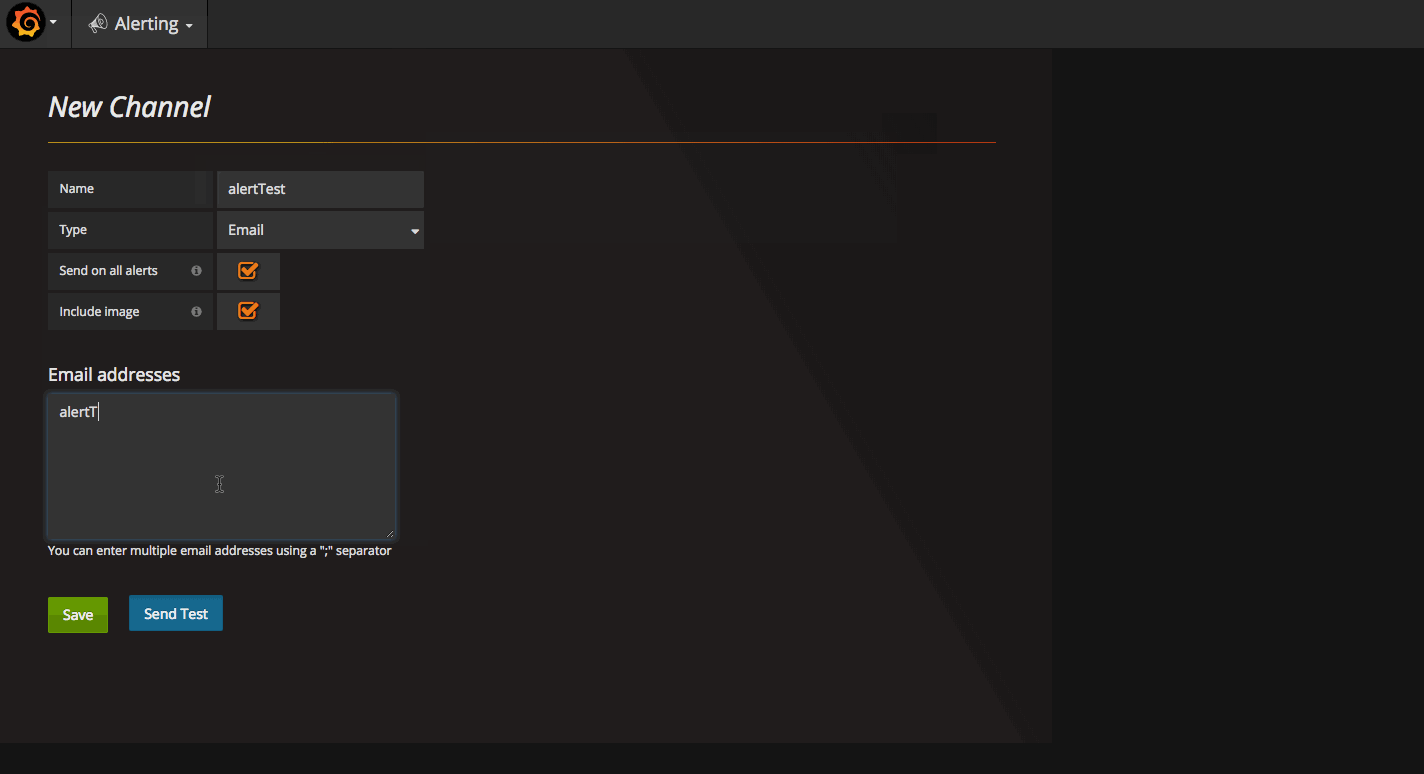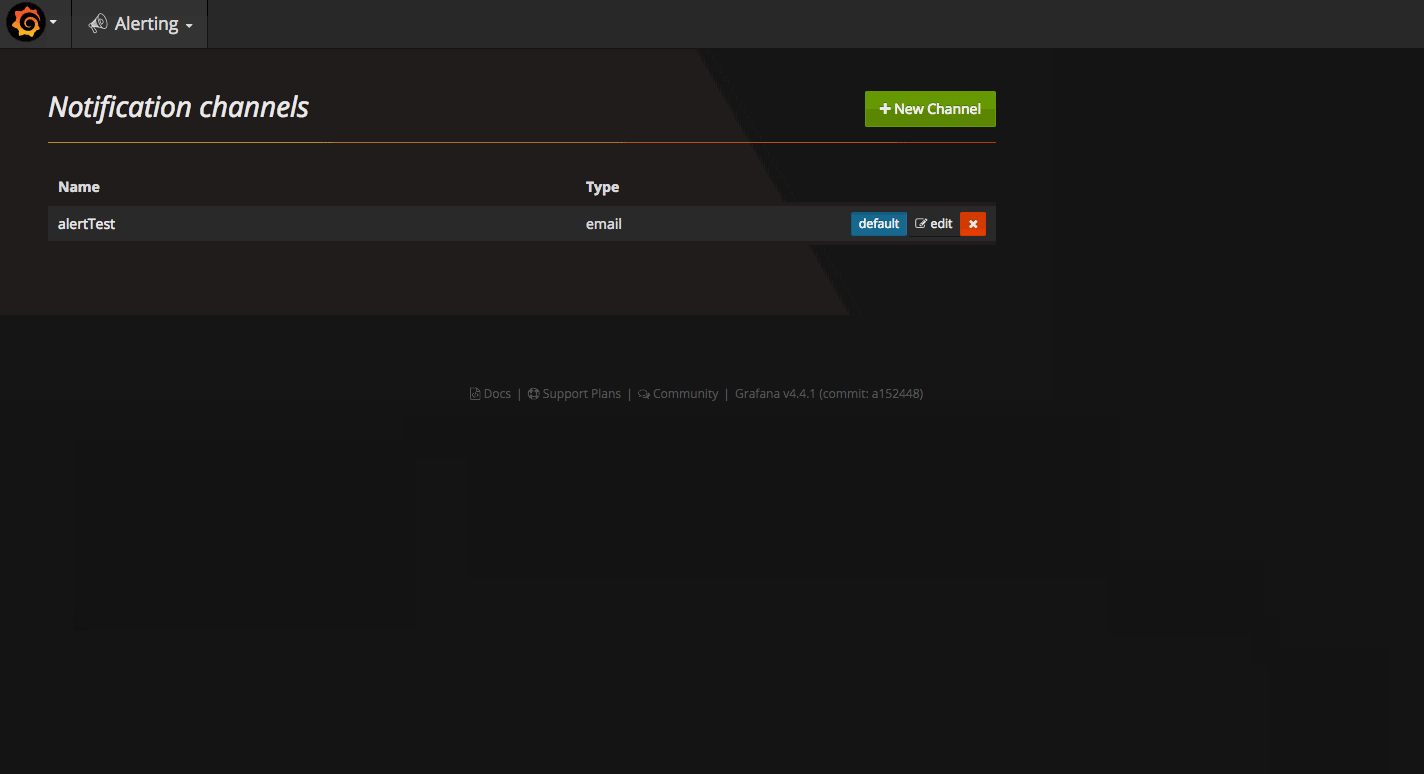
点击 New Channel 按钮,可以在 Type 选择包括 Slack, Email 邮箱,Webhook 等在内的多种报警方式。以
cpu usage高于 30% 发邮件报警为例(仅做测试使用,实际生产环境使用时请结合实际情况配置), 配置方法为: 编辑相应的panel, 选择Alert, 配置需要监控的查询及其阈值。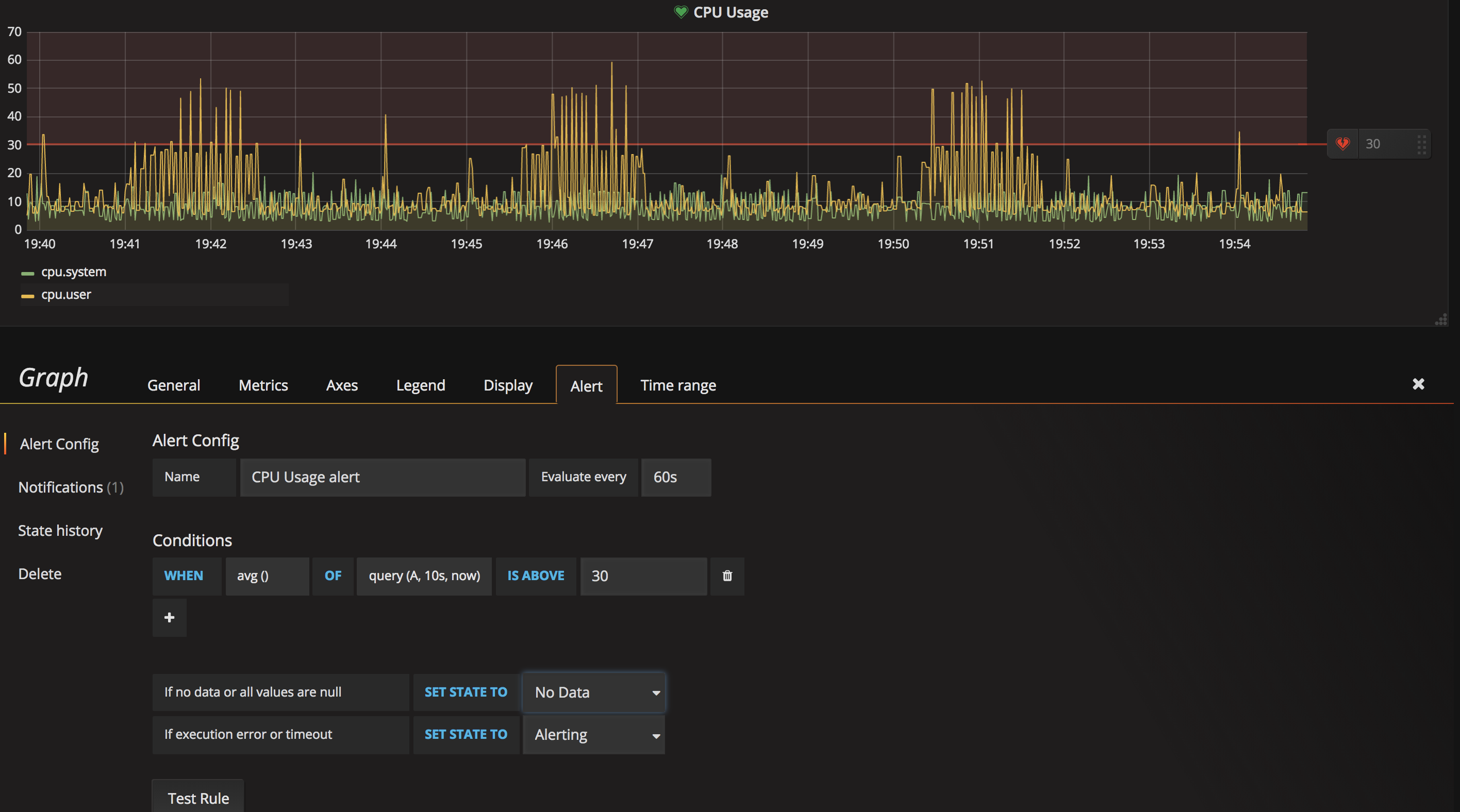
点击
State history可以看到报警历史。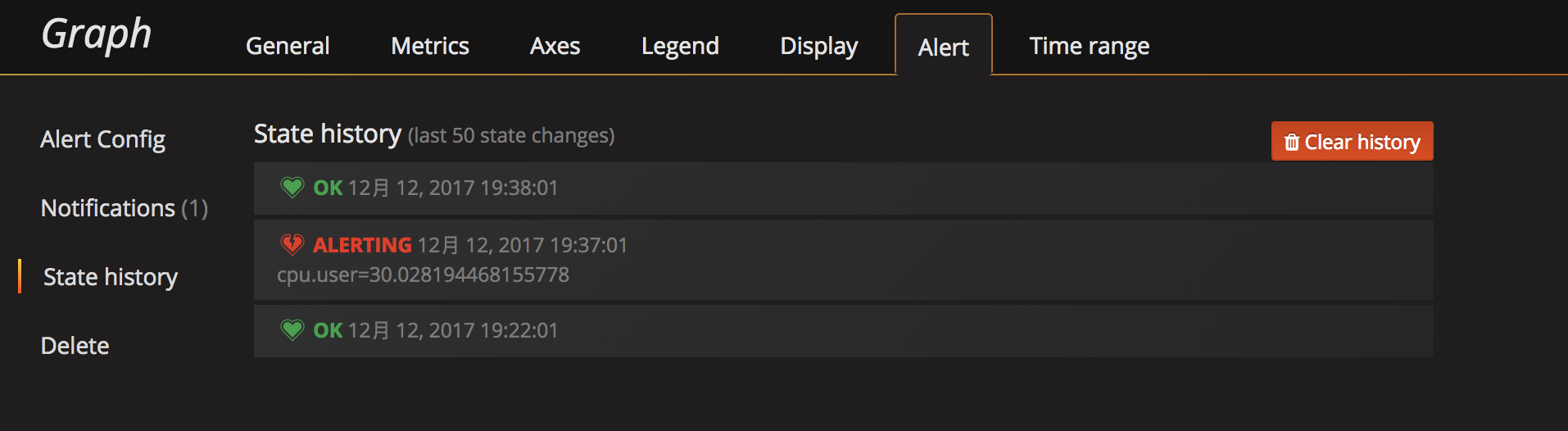
当有报警信息产生时,可以收到报警邮件。
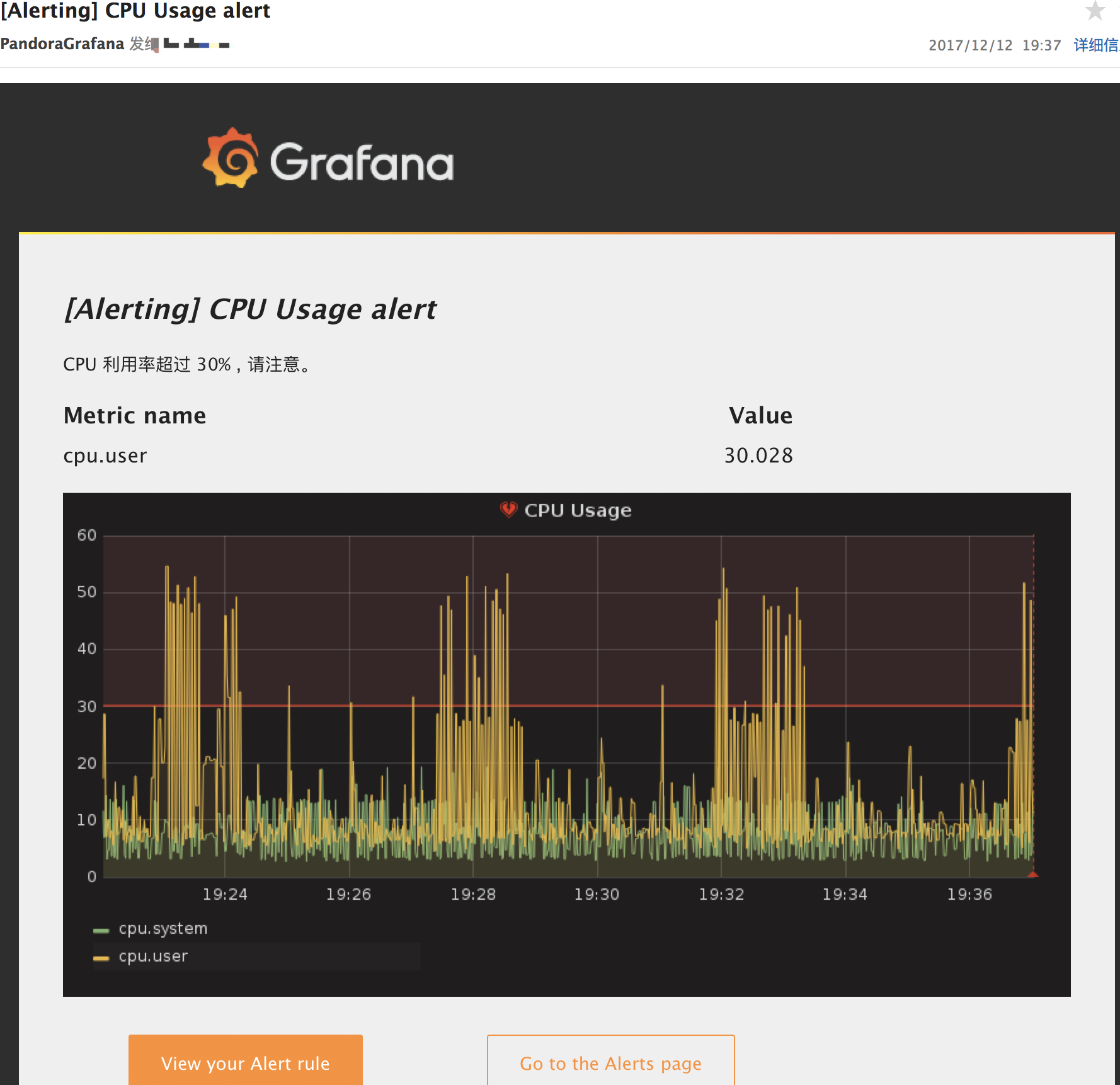
更多关于 Grafana 告警功能的配置可以参考 Grafana 告警文档
至此,一个详细的服务器性能监控系统搭建完成啦,快去体验吧!
