- 概念
- 数据源
- 数据计算
- 自定义计算
- Plugin管理
- UDF管理
- 魔法变量
- 自定义计算
- 数据导出
- 定时器
- 报警管理
- 批量计算任务批次管理
- 运行日志监控
概念
工作流(Workflow)是一个数据接收、计算、导出工具,把业务流程映射到页面上,在这里您的数据业务得到可视化,方便您更直观地来进行大数据分析流程管理。它的操作方式类似于思维脑图,直接在组件上右键或者通过拖拽在组件之间进行连线即可。

您可以通过访问七牛资源主页的 大数据工作流引擎 ,点击体验新版本进入工作流管理界面。
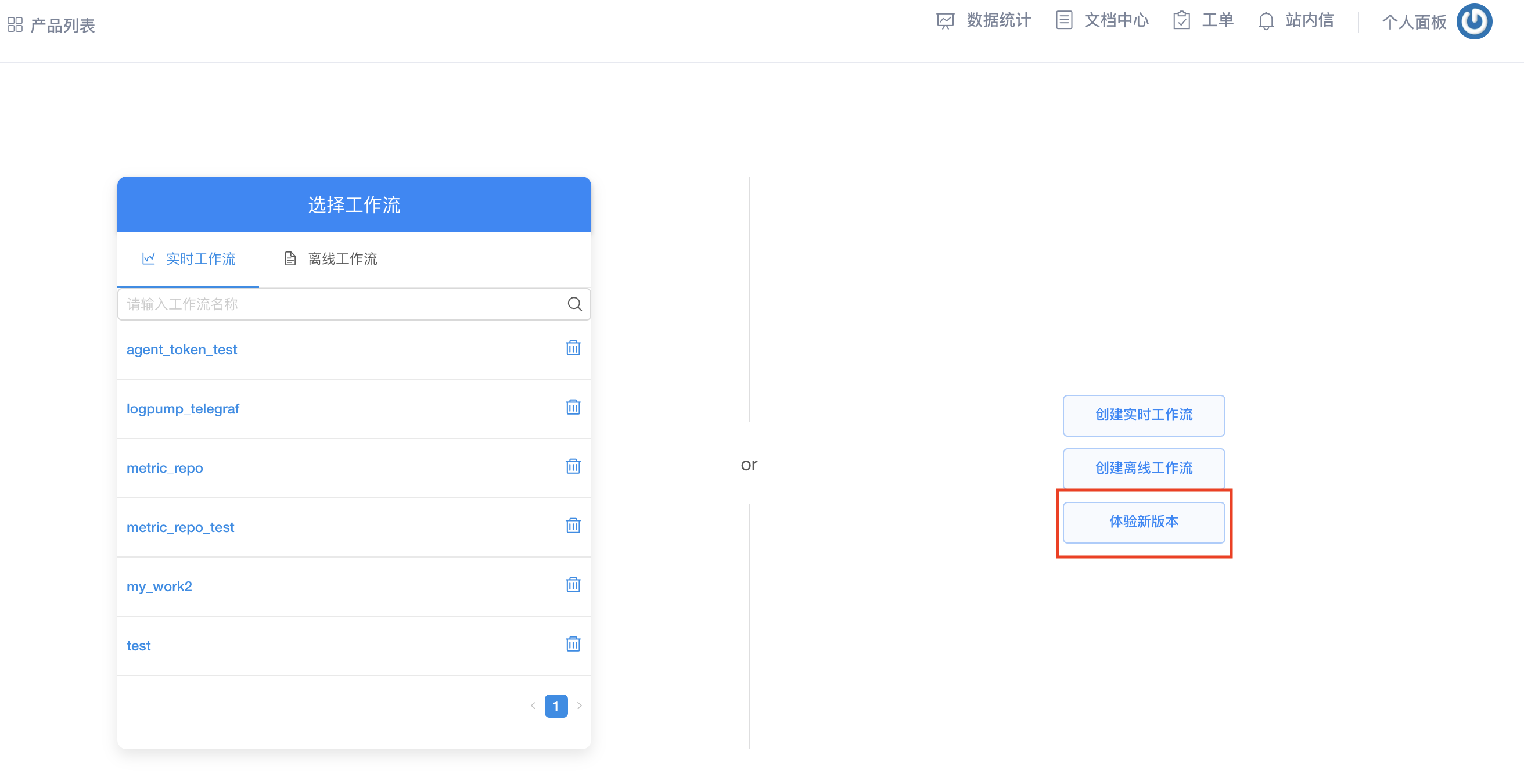
您可以根据需要创建一个或多个工作流,自行控制每一个工作流的启动和停止,方便您便捷地管理数据流。如果您给您的计算任务设置的是手动执行,那么您需要在工作流管理界面点击执行按钮,计算任务才会启动。通过多种功能自由组合,满足您的各种计算需求。
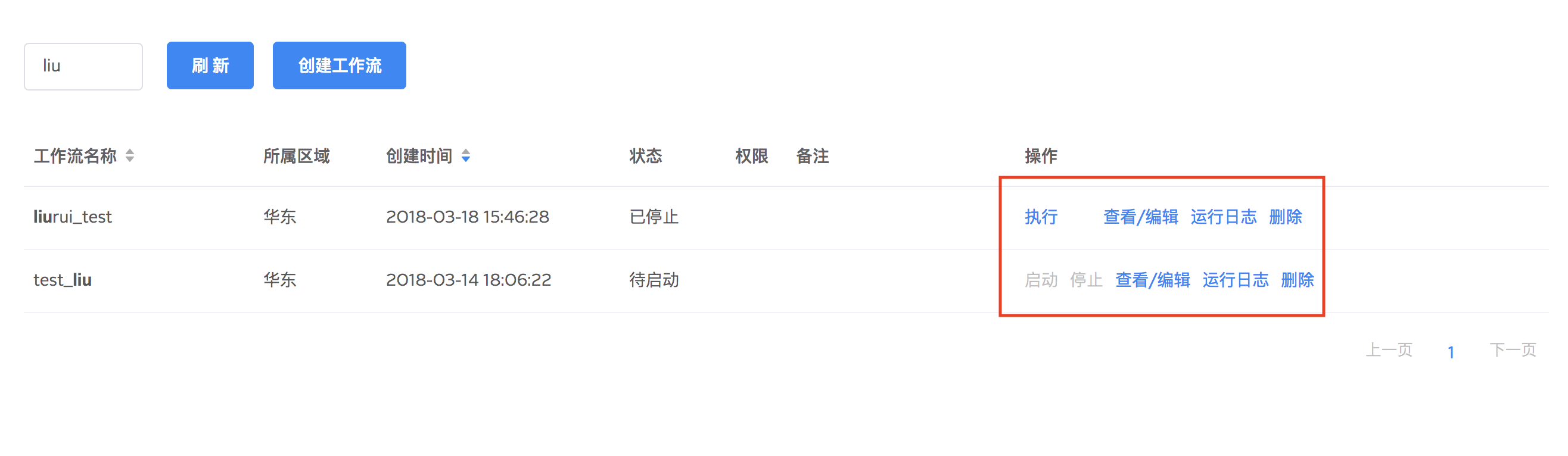
点击创建工作流进入工作流编辑界面。
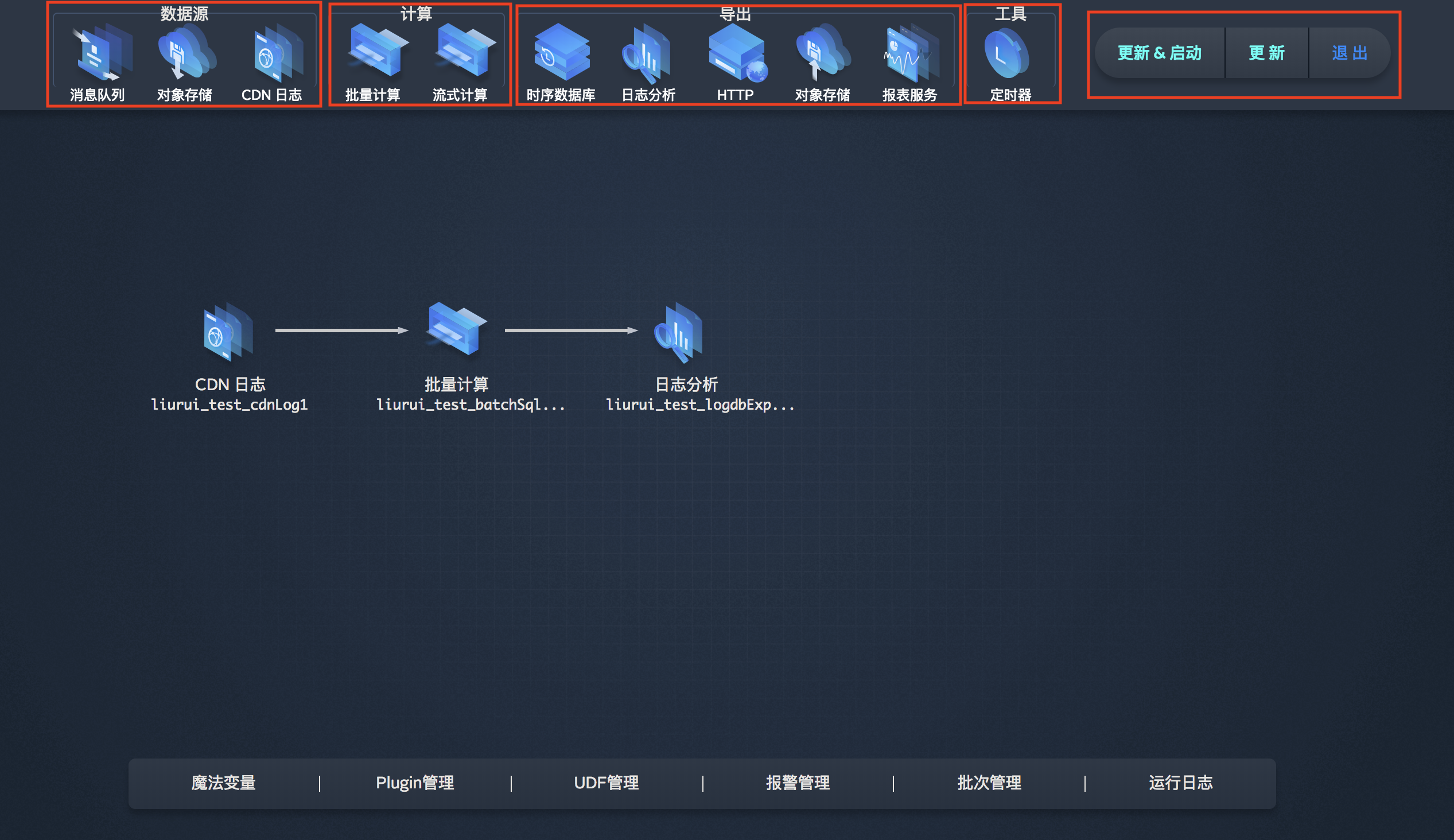
工作流提供3种组件:数据源、计算和导出帮助您打通数据业务,一个完整的工作流至少要包含一个数据源组件和一个数据导出组件。定时器工具在您创建批量计算任务的时候可以设置定时启动/循环启动。后面会详述。在界面右上角您可以看到功能按钮:更新&启动、更新、退出。当您业务逻辑还没整理好的时候,但是想保存现有的操作,您可以点击更新来保存您当前所做的操作,这样做可以大大节省您的工作量。
工作流中字段的数据结构可以是以下几种类型:
| 类型 | 解释 | 数据样例 |
|---|---|---|
| date | 日期类型,格式为RFC3339 |
2017-01-01T15:00:25Z07:00 |
| string | 字符串类型 | “qiniu.com” |
| long | 64位整数 | 1024 |
| float | 单精度64位浮点 | 322.00 |
| boolean | 布尔类型,值为true或false |
false |
工作流界面操作方法请观看视频教程。
视频教程:
数据源
数据源是工作流的起始节点,它可以接收实时上传的数据或读取离线存储的数据,在工作流中,目前支持以下几种类型的数据源:
| 名称 | 流式计算 | 批量计算 | 备注 |
|---|---|---|---|
| 消息队列 | yes | no | 只能作用于流式计算,实时接收用户上传的数据;每一条进入消息队列的数据,都会被存储2天时间,过期自动删除 |
| 对象存储 | no | yes | 只能作用于批量计算,可以一次性加载大量数据 |
| CDN | no | yes | 只能作用于批量计算,数据来源于七牛CDN服务 |
| HDFS | no | yes | 只能作用于批量计算,仅支持私有云,公有云不提供此服务 |
!> 注意:创建好工作流之后,无论是否启动该工作流,消息队列节点都可以接收数据。
消息队列节点相关参数填写
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 消息队列名称 |
| 字段信息 | 是 | 字段名称和字段类型 |
| IP来源 | 否 | 数据来源的IP信息 |
| 时间字段 | 否 | 数据接收的时间 |
| 服务器内部反转译 | 否 | 针对为了写入而被序列化产生的\t和\n进行反转译,恢复为\t和\n |
!> 注意:如果您的数据源新增了一些字段,可以使用添加新字段功能,更新消息队列。
对象存储节点相关参数填写
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 对象存储数据源节点名称 |
| 空间名称 | 是 | 您要读取的文件所在的bucket名称 |
| 文件类型 | 是 | 您要读取文件的格式 |
| 文件前缀 | 是 | 您要读取的文件名称的前缀 |
CDN日志节点相关参数填写
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | CDN日志数据源节点名称 |
| 域名 | 是 | 您的CDN服务的域名 |
| 文件过滤条件类型 | 是 | 日志产生的时间范围的选择方式(固定时间/相对时间) |
当文件过滤条件类型选择“相对时间”时,过滤条件里可以引入魔法变量。魔法变量后文会详述。
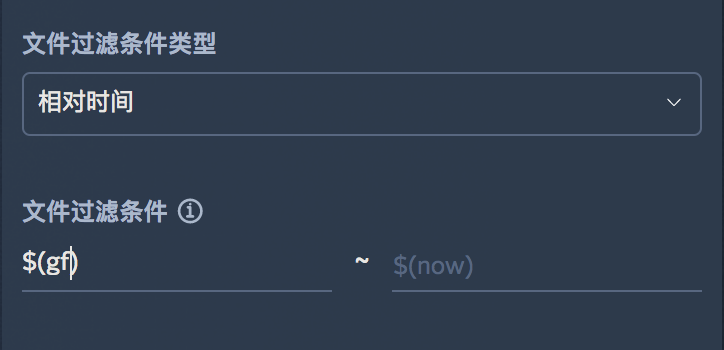
CDN日志数据源的字段类型不可更改,与七牛CDN服务产生的日志格式一致。
数据源节点的具体用法请观看视频教程。
视频教程:
数据计算
工作流提供两种计算模式供您选择:流式计算和批量计算;流式计算即实时计算,批量计算即离线计算。
计算的触发模式分为调度执行和手动执行,调度执行是指将工作流启动后,系统自动将自动开始运行,并按照条件执行调度;手动执行是指将工作流运行一遍后停止。流式计算的计算任务属于调度执行模式,批量计算的计算任务可以是调度执行模式(定时执行和循环执行)或者手动执行模式。
!> 注意1:一个工作流不能同时包含调度模式(流式计算/定时批量计算/循环批量计算)和手动执行模式(手动执行)。
!> 注意2:每一个工作流都可以同时包含一个或多个流式计算与批量计算,并且计算之间可以串行。
流式计算相关参数填写
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 计算任务名称 |
| 容器类型 | 是 | 计算任务需要的物理资源,不同的计算任务之间的计算资源互相隔离,互不影响 |
| 计算模式 | 是 | SQL语句计算/自定义计算,两种计算方式可以并存,并且优先执行自定义计算 |
| 间隔时间 | 是 | 计算任务的运行时间间隔 |
| 数据起始位置 | 是 | 从最早还是最新数据开始计算 |
批量计算相关参数填写
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 计算任务名称 |
| 容器类型 | 是 | 计算任务需要的资源 |
| 数据源名称 | 是 | 当数据源是对象存储节点的时候,支持多个数据源JOIN运算,因此需要指定数据源 |
| 数据库表名 | 是 | 执行SQL计算的数据库表名 |
| 触发方式 | 是 | 设置计算的触发方式:定时启动/循环启动/手动执行 |
计算节点的具体用法请观看视频教程。
视频教程:
自定义计算
流式计算中,您可能遇到SQL满足不了的计算需求,这时您可以通过自定义计算完成。在这里我们提供引用Plugin和UDF帮您完成自定义计算。
Plugin管理
通过下载我们提供的代码模板,在此基础上编写您的代码(输入类、输出类、业务逻辑代码),打成Jar包。在工作流的工作界面,您可以通过 Plugin管理 上传您的Jar包到工作流,之后您就可以在流式计算中引用您自定义的Plugin来实现更为复杂的数据计算啦!
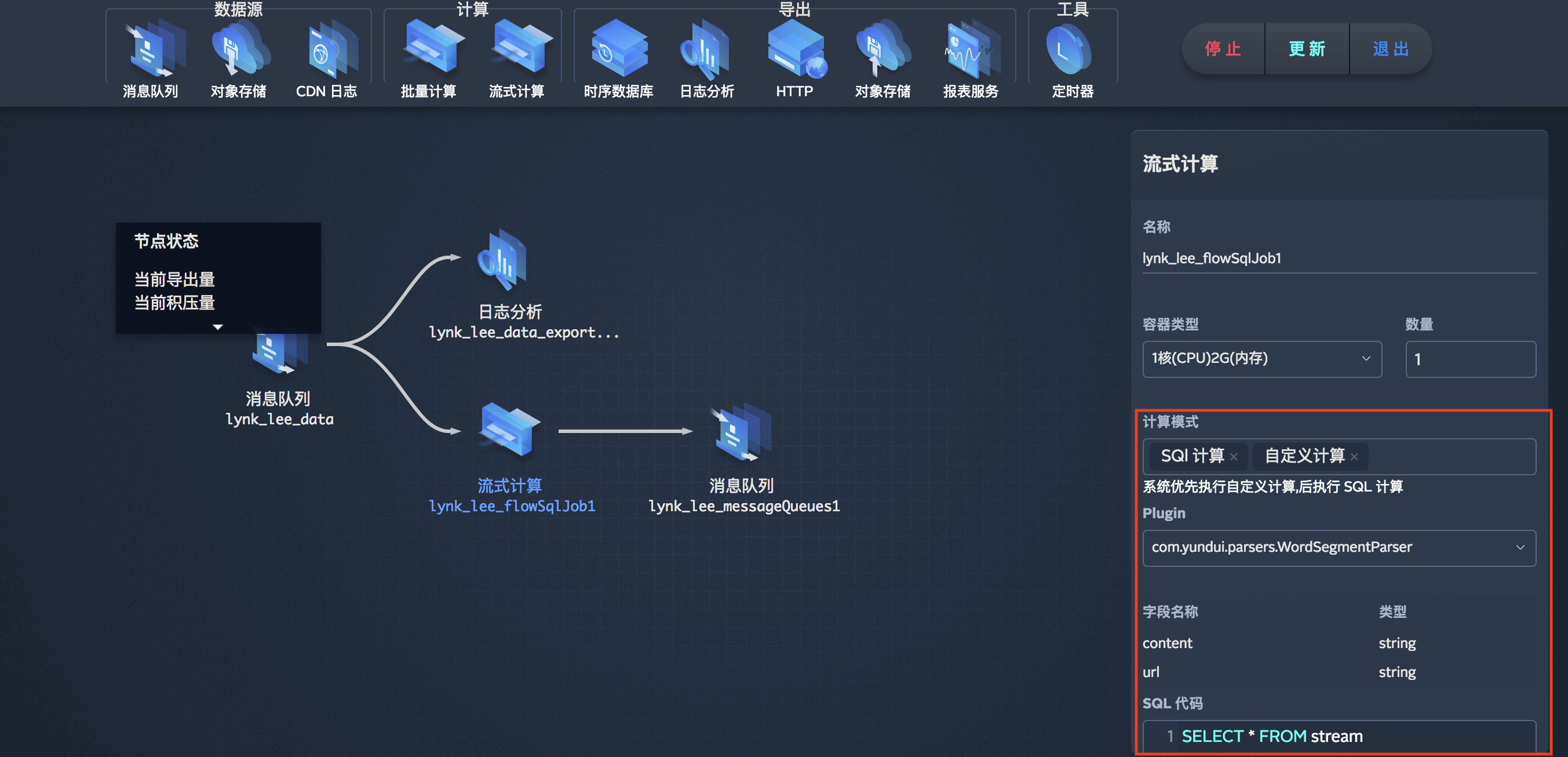
!> 注意:目前Plugin仅支持Java语言。
Plugin模板下载链接—->>>点此跳转
Plugin具体用法请观看视频教程。
视频教程:
UDF管理
UDF(User-Defined Function):用户自定义函数。
UDF可以在SQL计算模式中使用,Workflow提供了提供了大约50多种内置UDF函数;如果这些函数不能满足您的需求,那么您也可以自行编写UDF,提交Jar包并添加到UDF函数管理,提交后即可使用。

自定义UDF的过程与自定义Plugin类似,如下:
UDF模板下载链接—->>>点此跳转
解压后,使用Java IDE导入Pandora-UDF项目。
等待项目依赖加载完成后,可以在 src/main/java/com.pandora/ 目录下查看一个简单的示例。
这个示例中包含了一个名为 SimpleUdf的Class,在这个Class中有4个方法:
1. String parseTime(String t)将 Input RFC3339 格式转为 date time 时间格式@param input rfc3339 格式,形如 2017-04-05T16:41:42.651614Z@return 返回date time格式时间 形如 2017-04-05 16:41:42如 parseTime("2017-04-05T16:41:42.651614Z")2. String parseTime(long t)将时间戳转为 date time 时间格式@param input 时间戳,单位为毫秒@return 返回date time格式时间 形如 2017-04-05 16:41:42如 parseTime(1499324233000)3. String parseTime(long t, String unit)将 Input RFC3339 格式转为 date time 时间格式@param input 时间戳,单位为毫秒@param unit 指定时间戳的单位,支持 s (秒), ms(毫秒), us(微妙), ns (纳秒)@return 返回date time格式时间 形如 2017-04-05 16:41:42如 parseTime(1499324233000, "ms")4. String parseTime(long t, String unit)将 Input RFC3339 格式转为 date time 时间格式@param input 时间戳,单位为毫秒@param unit 指定时间精度,1毫秒等于多少该精度单位时间@return 返回date time格式时间 形如 2017-04-05 16:41:42如 parseTime(149932423300000000, 100000) 解析百纳秒时间戳
您可以在 src/main/java/com.pandora/ 目录下新建Class和方法,并在方法中编写UDF逻辑,代码编写完成后,需要将这个工程打成Jar包并上传至Workflow,新增到自定义函数里,然后就可以使用这个UDF了。
!> 注意:Jar包名称中不可包含-、_号。
在SQL中使用UDF:
SELECTparseTime(t1) t1,parseTime(t2) t2,parseTime(t3, "s") t3,parseTime(t4, 100000) t4fromstream
魔法变量
魔法变量的概念类似于编程语言中的变量,即您可以定义一个变量,在数据计算中或者过滤条件中引用。目前魔法变量仅支持时间类型的值。
目前系统提供了8个内置变量,只能引用,不可修改和删除:
| 变量名称 | 类型 | 值 | 格式 |
|---|---|---|---|
| date | 时间表达式 | $(date) | yyyy-MM-dd |
| day | 时间表达式 | $(day) | dd |
| hour | 时间表达式 | $(hour) | HH |
| min | 时间表达式 | $(min) | mm |
| mon | 时间表达式 | $(mon) | MM |
| now | 时间表达式 | $(now) | yyyy-MM-dd HH |
| sec | 时间表达式 | $(sec) | ss |
| year | 时间表达式 | $(year) | yyyy |
 ss
ss用户也可以自行创建魔法变量,并且创建的魔法变量的值可以引用系统内置变量。

当我们需要使用魔法变量的时候,只需要输入 $(变量名称) 即可,如:
select * from stream where time = $(now)
数据导出
将数据源或计算任务中的数据导出到指定的地址。
目前我们支持将数据导出到以下地址:
1. 指定一个日志分析服务的日志仓库;2. 指定一个时序数据库的数据仓库下的序列;3. 指定一个HTTP服务器地址;4. 指定一个对象存储的Bucket;5. 指定一个报表工作室的数据仓库下的数据表;
导出到日志分析填写参数
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 导出节点名称 |
| 仓库名称 | 是 | 您要进行日志分析的仓库名称,可以选择已有仓库或者创建新仓库 |
| 数据存储时限 | 是 | 导出的数据存储在日志仓库的时间限制 |
| 丢弃无效数据 | 否 | 是否忽略无效数据 |
导出到时序数据仓库填写参数
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 导出节点名称 |
| 数据库名称 | 是 | 您要进行时序数据分析的数据仓库名称 |
| 序列名称 | 是 | 数据仓库的表名,数据将会被导入到这个表当中 |
| 数据存储时限 | 否 | 导出的数据存储在时序数据仓库的时间限制 |
| 时间戳 | 是 | 数据导出的时间,默认使用当前时间 |
| 数据起始位置 | 否 | 从最早还是最新数据开始导出 |
| 丢弃无效数据 | 否 | 是否忽略无效数据 |
导出到HTTP地址填写参数
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 导出节点名称 |
| 服务器地址 | 是 | ip或域名,例如:https://pipeline.qiniu.com 或 https://127.0.0.1:7758 |
| 请求资源路径 | 是 | 具体地址,例如:/test/repos |
| 导出类型 | 是 | 导出的文件格式 |
| 数据起始位置 | 是 | 从最早还是最新数据开始导出,默认从最新数据导出 |
导出到对象存储填写参数
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 导出节点名称 |
| 空间名称 | 是 | 导出的对象存储的bucket名称 |
| 文件前缀 | 是 | 导出的文件名称的前缀 |
| 导出类型 | 是 | 可以将文件导成四种格式:json、csv、text、parquet;其中json、csv和text可以选择是否将文件压缩,而parquet无需选择,默认自动压缩,压缩比大概为3-20倍 |
| 文件压缩 | 是 | 是否开启文件压缩功能 |
| 最大文件保存天数 | 是 | 数据导出在对象存储中的时限,以天为单位,超过这个时间范围的文件会被自动删除,当该字段为0或者为空时,则永久储存 |
| 文件分割策略 | 是 | 文件切割策略,可以按照文件大小切割:文件大小超过设置的值则进行切割;也可以按照时间间隔切割:文件导出时长超过设置的值则进行切割;也可以两者方式只要满足一种即进行切割 |
| 数据起始位置 | 是 | 从最早还是最新数据开始导出,默认从最新数据导出 |
!> 关于文件前缀,默认值为空(生成文件名会自动加上时间戳格式为yyyy-MM-dd-HH-mm-ss),支持魔法变量。
前缀用法说明:
1.前缀使用魔法变量
假如前缀的取值为kodo-parquet/date=$(year)-$(mon)-$(day)/hour=$(hour)/min=$(min)/$(sec),且生成某一文件时的北京标准时间为2017-01-12 15:30:00, 则前缀将被解析为kodo-parquet/date=2017-01-12/hour=15/min=30/00,其中的魔法变量$(year)、$(mon)、$(day)、$(hour)、$(min)、$(sec)分别对应文件生成时间2017-01-12 15:30:00的年、月、日、时、分、秒。
2.前缀使用默认值
假如生成某一文件时的北京标准时间为2017-01-12 15:30:00, 则前缀将被解析为2017-01-12-15-30-00。
导出到报表服务填写参数
| 参数 | 必填 | 说明 |
|---|---|---|
| 名称 | 是 | 导出节点名称 |
| 数据库名称 | 是 | 导出到报表服务的数据库名称 |
| 数据表名称 | 是 | 导出的数据库的具体表名 |
| 数据起始位置 | 是 | 从最早还是最新数据开始导出,默认从最新数据导出 |
定时器
Workflow提供定时器功能,当您想为批量计算设置循环或定时规则时,您可以直接将定时器工具拖拽到批量计算节点上,然后在参数里填写相应的定时规则,您的批量运算任务就可以有条不紊的按照您设定的规则定时运行啦,非常方便!
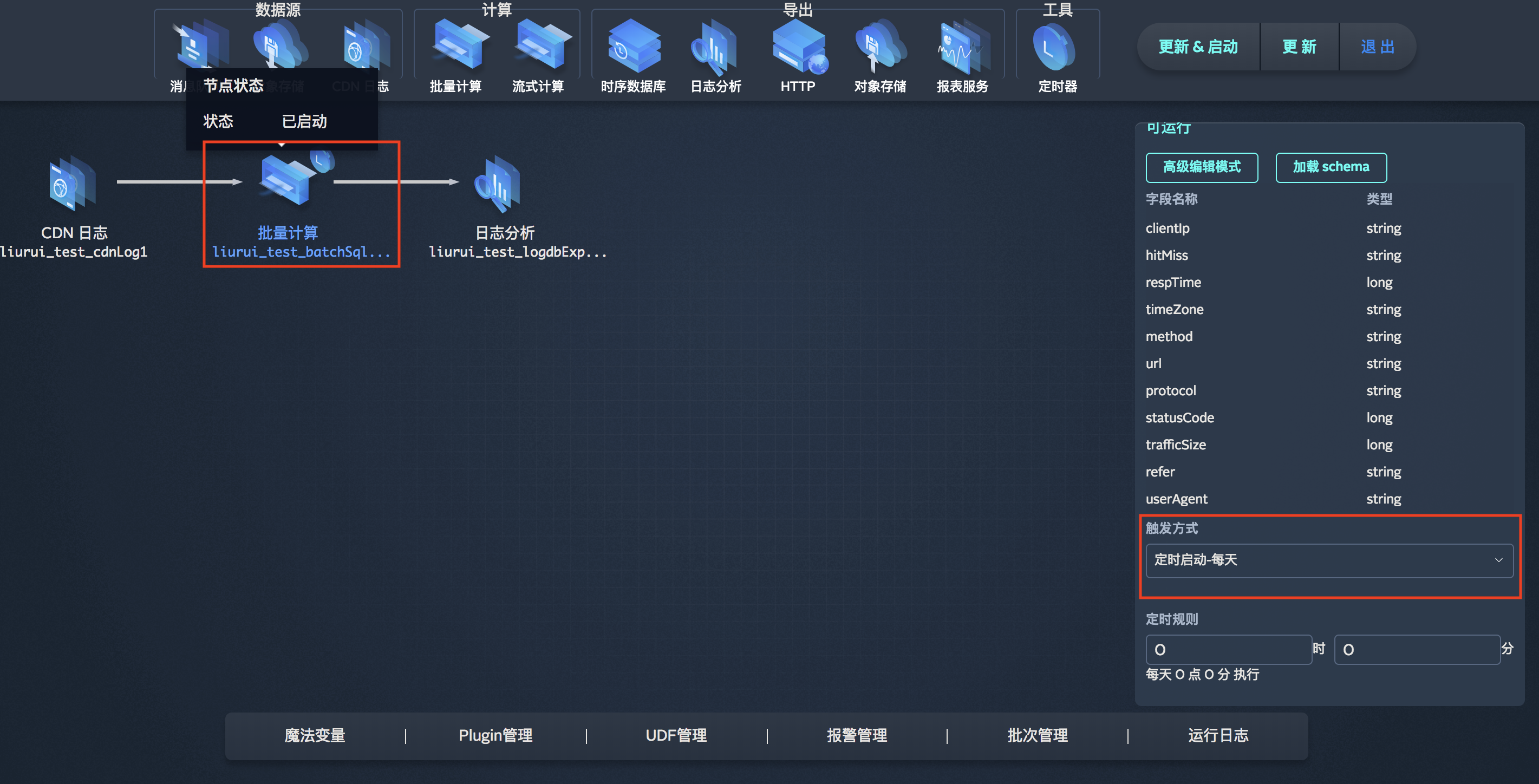
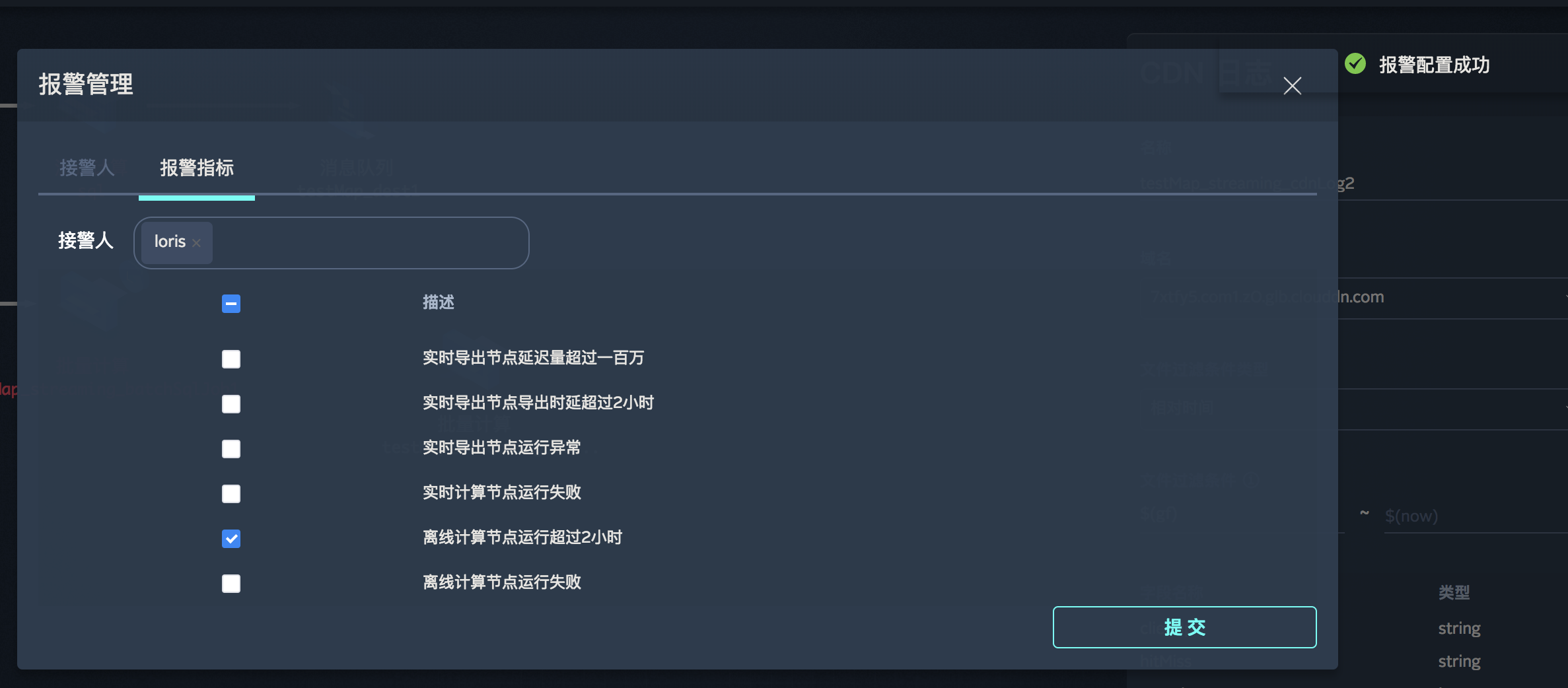
报警管理
Workflow支持报警管理,您可以填写报警人相关信息和报警指标,如果节点的运行情况满足您选择的报警指标,您就可以收到报警通知啦!

批量计算任务批次管理
当您的计算任务是手动执行的时候,Workflow提供任务批次管理,您可以看到您的数据运行任务执行的状态(运行中、成功、失败、就绪、已停止),对于停止或失败的任务,您可以对它进行重新执行操作。

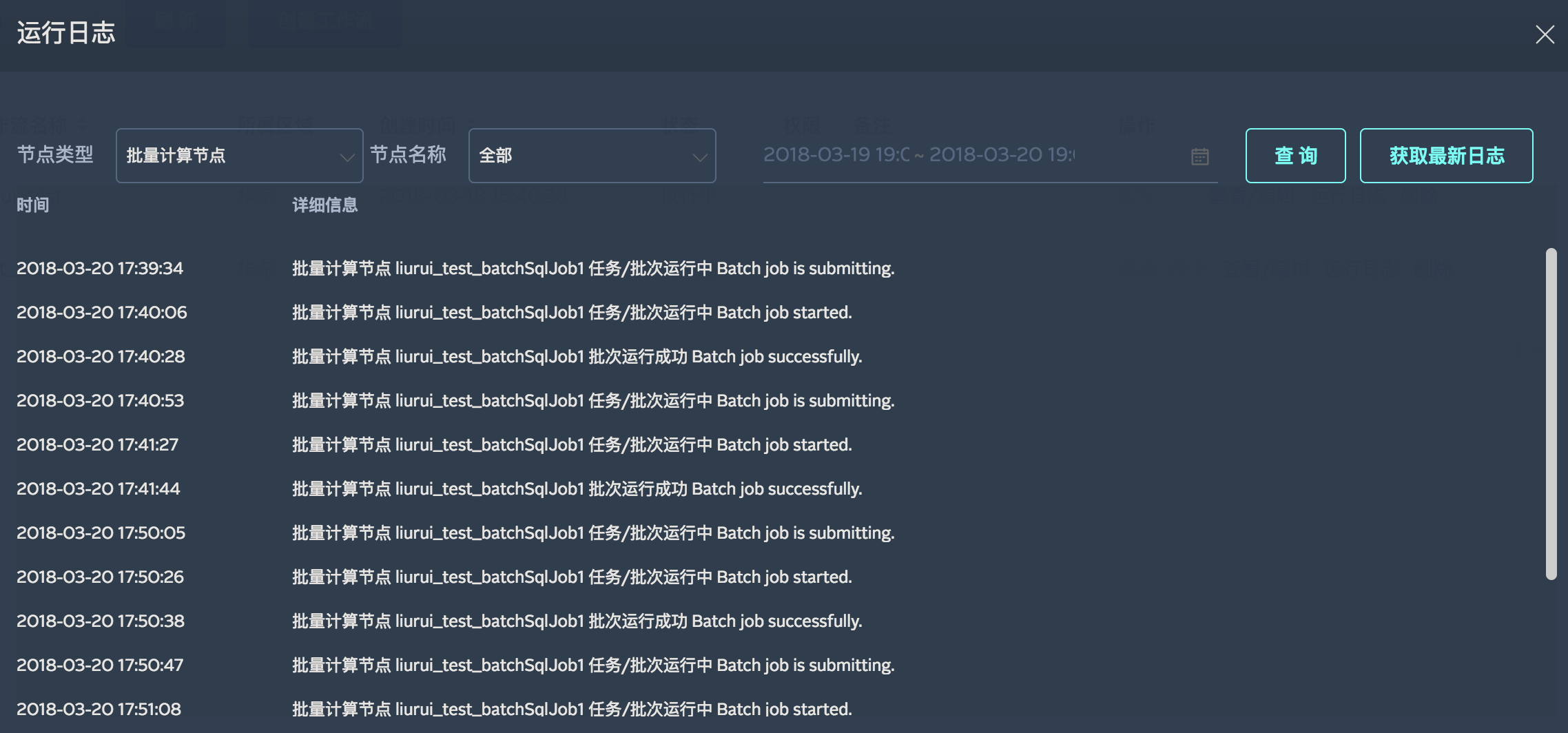
运行日志监控
Workflow提供节点的运行日志监控,您可以选择数据节点(导出节点、流式计算节点、批量计算节点)来查看各节点的运行日志,帮您宏观监控数据的运行情况,及时发现问题。