 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 访问 externalTrafficPolicy 为 Local 的 Service 对应 LB 有时超时
访问 externalTrafficPolicy 为 Local 的 Service 对应 LB 有时超时
现象:用户在 TKE 创建了公网 LoadBalancer 类型的 Service,externalTrafficPolicy 设为了 Local,访问这个 Service 对应的公网 LB 有时会超时。
externalTrafficPolicy 为 Local 的 Service 用于在四层获取客户端真实源 IP,官方参考文档:Source IP for Services with Type=LoadBalancer
TKE 的 LoadBalancer 类型 Service 实现是使用 CLB 绑定所有节点对应 Service 的 NodePort,CLB 不做 SNAT,报文转发到 NodePort 时源 IP 还是真实的客户端 IP,如果 NodePort 对应 Service 的 externalTrafficPolicy 不是 Local 的就会做 SNAT,到 pod 时就看不到客户端真实源 IP 了,但如果是 Local 的话就不做 SNAT,如果本机 node 有这个 Service 的 endpoint 就转到对应 pod,如果没有就直接丢掉,因为如果转到其它 node 上的 pod 就必须要做 SNAT,不然无法回包,而 SNAT 之后就无法获取真实源 IP 了。
LB 会对绑定节点的 NodePort 做健康检查探测,检查 LB 的健康检查状态: 发现这个 NodePort 的所有节点都不健康 !!!
那么问题来了:
- 为什么会全不健康,这个 Service 有对应的 pod 实例,有些节点上是有 endpoint 的,为什么它们也不健康?
- LB 健康检查全不健康,但是为什么有时还是可以访问后端服务?
跟 LB 的同学确认: 如果后端 rs 全不健康会激活 LB 的全死全活逻辑,也就是所有后端 rs 都可以转发。
那么有 endpoint 的 node 也是不健康这个怎么解释?
在有 endpoint 的 node 上抓 NodePort 的包: 发现很多来自 LB 的 SYN,但是没有响应 ACK。
看起来报文在哪被丢了,继续抓下 cbr0 看下: 发现没有来自 LB 的包,说明报文在 cbr0 之前被丢了。
再观察用户集群环境信息:
- k8s 版本1.12
- 启用了 ipvs
- 只有 local 的 service 才有异常
尝试新建一个 1.12 启用 ipvs 和一个没启用 ipvs 的测试集群。也都创建 Local 的 LoadBalancer Service,发现启用 ipvs 的测试集群复现了那个问题,没启用 ipvs 的集群没这个问题。
再尝试创建 1.10 的集群,也启用 ipvs,发现没这个问题。
看起来跟集群版本和是否启用 ipvs 有关。
1.12 对比 1.10 启用 ipvs 的集群: 1.12 的会将 LB 的 EXTERNAL-IP 绑到 kube-ipvs0 上,而 1.10 的不会:
$ ip a show kube-ipvs0 | grep -A2 170.106.134.124inet 170.106.134.124/32 brd 170.106.134.124 scope global kube-ipvs0valid_lft forever preferred_lft forever
- 170.106.134.124 是 LB 的公网 IP
- 1.12 启用 ipvs 的集群将 LB 的公网 IP 绑到了
kube-ipvs0网卡上
kube-ipvs0 是一个 dummy interface,实际不会接收报文,可以看到它的网卡状态是 DOWN,主要用于绑 ipvs 规则的 VIP,因为 ipvs 主要工作在 netfilter 的 INPUT 链,报文通过 PREROUTING 链之后需要决定下一步该进入 INPUT 还是 FORWARD 链,如果是本机 IP 就会进入 INPUT,如果不是就会进入 FORWARD 转发到其它机器。所以 k8s 利用 kube-ipvs0 这个网卡将 service 相关的 VIP 绑在上面以便让报文进入 INPUT 进而被 ipvs 转发。
当 IP 被绑到 kube-ipvs0 上,内核会自动将上面的 IP 写入 local 路由:
$ ip route show table local | grep 170.106.134.124local 170.106.134.124 dev kube-ipvs0 proto kernel scope host src 170.106.134.124
内核认为在 local 路由里的 IP 是本机 IP,而 linux 默认有个行为: 忽略任何来自非回环网卡并且源 IP 是本机 IP 的报文。而 LB 的探测报文源 IP 就是 LB IP,也就是 Service 的 EXTERNAL-IP 猜想就是因为这个 IP 被绑到 kube-ipvs0,自动加进 local 路由导致内核直接忽略了 LB 的探测报文。
带着猜想做实现, 试一下将 LB IP 从 local 路由中删除:
ip route del table local local 170.106.134.124 dev kube-ipvs0 proto kernel scope host src 170.106.134.124
发现这个 node 的在 LB 的健康检查的状态变成健康了! 看来就是因为这个 LB IP 被绑到 kube-ipvs0 导致内核忽略了来自 LB 的探测报文,然后 LB 收不到回包认为不健康。
那为什么其它厂商没反馈这个问题?应该是 LB 的实现问题,腾讯云的公网 CLB 的健康探测报文源 IP 就是 LB 的公网 IP,而大多数厂商的 LB 探测报文源 IP 是保留 IP 并非 LB 自身的 VIP。
如何解决呢? 发现一个内核参数: accept_local 可以让 linux 接收源 IP 是本机 IP 的报文。
试了开启这个参数,确实在 cbr0 收到来自 LB 的探测报文了,说明报文能被 pod 收到,但抓 eth0 还是没有给 LB 回包。
为什么没有回包? 分析下五元组,要给 LB 回包,那么 目的IP:目的Port 必须是探测报文的 源IP:源Port,所以目的 IP 就是 LB IP,由于容器不在主 netns,发包经过 veth pair 到 cbr0 之后需要再经过 netfilter 处理,报文进入 PREROUTING 链然后发现目的 IP 是本机 IP,进入 INPUT 链,所以报文就出不去了。再分析下进入 INPUT 后会怎样,因为目的 Port 跟 LB 探测报文源 Port 相同,是一个随机端口,不在 Service 的端口列表,所以没有对应的 IPVS 规则,IPVS 也就不会转发它,而 kube-ipvs0 上虽然绑了这个 IP,但它是一个 dummy interface,不会收包,所以报文最后又被忽略了。
再看看为什么 1.12 启用 ipvs 会绑 EXTERNAL-IP 到 kube-ipvs0,翻翻 k8s 的 kube-proxy 支持 ipvs 的 proposal,发现有个地方说法有点漏洞:

LB 类型 Service 的 status 里有 ingress IP,实际就是 kubectl get service 看到的 EXTERNAL-IP,这里说不会绑定这个 IP 到 kube-ipvs0,但后面又说会给它创建 ipvs 规则,既然没有绑到 kube-ipvs0,那么这个 IP 的报文根本不会进入 INPUT 被 ipvs 模块转发,创建的 ipvs 规则也是没用的。
后来找到作者私聊,思考了下,发现设计上确实有这个问题。
看了下 1.10 确实也是这么实现的,但是为什么 1.12 又绑了这个 IP 呢? 调研后发现是因为 #59976 这个 issue 发现一个问题,后来引入 #63066 这个 PR 修复的,而这个 PR 的行为就是让 LB IP 绑到 kube-ipvs0,这个提交影响 1.11 及其之后的版本。
#59976 的问题是因为没绑 LB IP到 kube-ipvs0 上,在自建集群使用 MetalLB 来实现 LoadBalancer 类型的 Service,而有些网络环境下,pod 是无法直接访问 LB 的,导致 pod 访问 LB IP 时访问不了,而如果将 LB IP 绑到 kube-ipvs0 上就可以通过 ipvs 转发到 LB 类型 Service 对应的 pod 去, 而不需要真正经过 LB,所以引入了 #63066 这个PR。
临时方案: 将 #63066 这个 PR 的更改回滚下,重新编译 kube-proxy,提供升级脚本升级存量 kube-proxy。
如果是让 LB 健康检查探测支持用保留 IP 而不是自身的公网 IP ,也是可以解决,但需要跨团队合作,而且如果多个厂商都遇到这个问题,每家都需要为解决这个问题而做开发调整,代价较高,所以长期方案需要跟社区沟通一起推进,所以我提了 issue,将问题描述的很清楚: #79783
小思考: 为什么 CLB 可以不做 SNAT ? 回包目的 IP 就是真实客户端 IP,但客户端是直接跟 LB IP 建立的连接,如果回包不经过 LB 是不可能发送成功的呀。
是因为 CLB 的实现是在母机上通过隧道跟 CVM 互联的,多了一层封装,回包始终会经过 LB。
就是因为 CLB 不做 SNAT,正常来自客户端的报文是可以发送到 nodeport,但健康检查探测报文由于源 IP 是 LB IP 被绑到 kube-ipvs0 导致被忽略,也就解释了为什么健康检查失败,但通过LB能访问后端服务,只是有时会超时。那么如果要做 SNAT 的 LB 岂不是更糟糕,所有报文都变成 LB IP,所有报文都会被忽略?
我提的 issue 有回复指出,AWS 的 LB 会做 SNAT,但它们不将 LB 的 IP 写到 Service 的 Status 里,只写了 hostname,所以也不会绑 LB IP 到 kube-ipvs0:
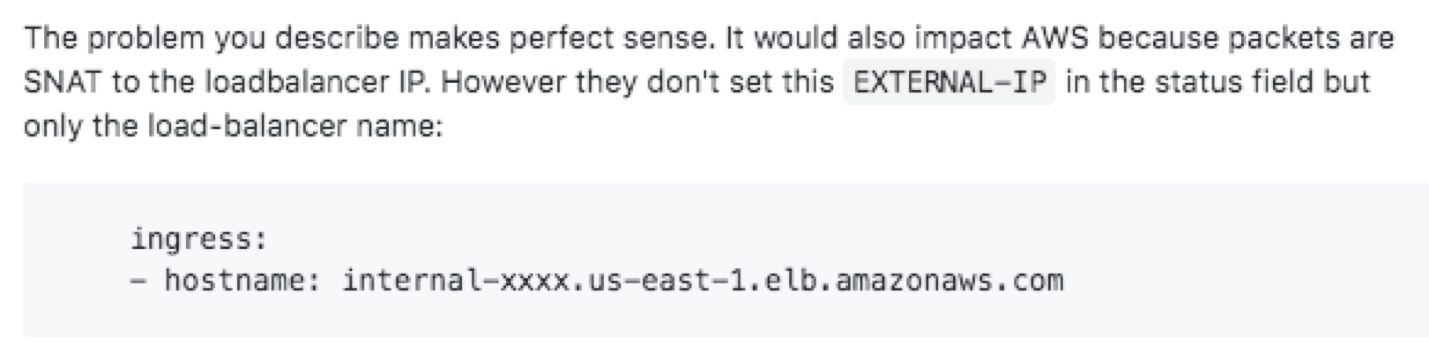
但是只写 hostname 也得 LB 支持自动绑域名解析,并且个人觉得只写 hostname 很别扭,通过 kubectl get svc 或者其它 k8s 管理系统无法直接获取 LB IP,这不是一个好的解决方法。
我提了 #79976 这个 PR 可以解决问题: 给 kube-proxy 加 --exclude-external-ip 这个 flag 控制是否为 LB IP创建 ipvs 规则和绑定 kube-ipvs0。
但有人担心增加 kube-proxy flag 会增加 kube-proxy 的调试复杂度,看能否在 iptables 层面解决: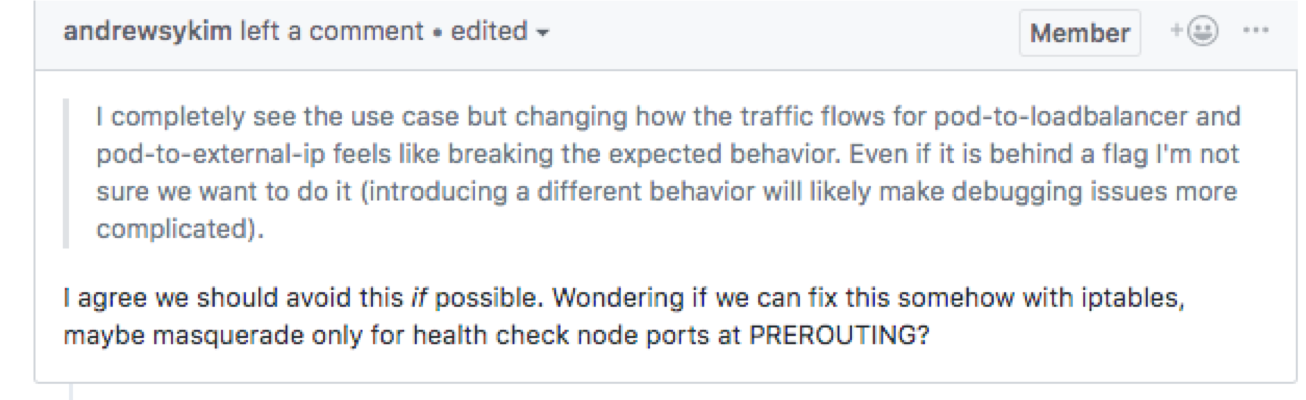
仔细一想,确实可行,打算有空实现下,重新提个 PR:
