 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 爬取豆瓣电影 Top250
- 目标
- 开始
- 安装
- 运行
- 代码片段
- 1、获取所有分页
- 2、分析豆瓣电影信息
- 数据
爬取豆瓣电影 Top250
爬虫是标配了,看数据那一刻很有趣。第一个就从最最最简单最基础的爬虫开始写起吧!
项目地址:https://github.com/go-crawler/douban-movie
目标
我们的目标站点是 豆瓣电影 Top250,估计大家都很眼熟了
本次爬取8个字段,用于简单的概括分析。具体的字段如下:
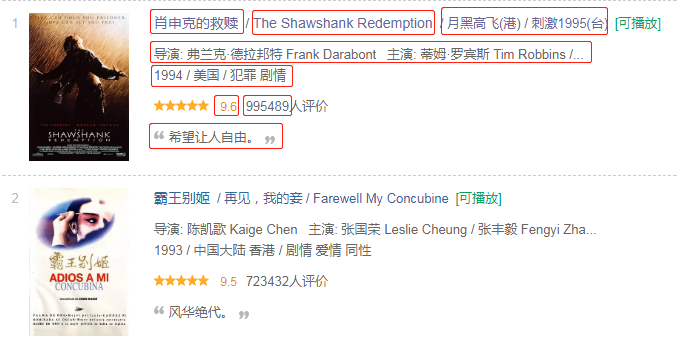
简单的分析一下目标源
- 一页共25条
- 含分页(共10页)且分页规则是正常的
- 每一项的数据字段排序都是规则且不变
开始
由于量不大,我们的爬取步骤如下
- 分析页面,获取所有的分页
- 分析页面,循环爬取所有页面的电影信息
- 爬取的电影信息入库
安装
$ go get -u github.com/PuerkitoBio/goquery
运行
$ go run main.go
代码片段
1、获取所有分页
func ParsePages(doc *goquery.Document) (pages []Page) {pages = append(pages, Page{Page: 1, Url: ""})doc.Find("#content > div > div.article > div.paginator > a").Each(func(i int, s *goquery.Selection) {page, _ := strconv.Atoi(s.Text())url, _ := s.Attr("href")pages = append(pages, Page{Page: page,Url: url,})})return pages}
2、分析豆瓣电影信息
func ParseMovies(doc *goquery.Document) (movies []Movie) {doc.Find("#content > div > div.article > ol > li").Each(func(i int, s *goquery.Selection) {title := s.Find(".hd a span").Eq(0).Text()...movieDesc := strings.Split(DescInfo[1], "/")year := strings.TrimSpace(movieDesc[0])area := strings.TrimSpace(movieDesc[1])tag := strings.TrimSpace(movieDesc[2])star := s.Find(".bd .star .rating_num").Text()comment := strings.TrimSpace(s.Find(".bd .star span").Eq(3).Text())compile := regexp.MustCompile("[0-9]")comment = strings.Join(compile.FindAllString(comment, -1), "")quote := s.Find(".quote .inq").Text()...log.Printf("i: %d, movie: %v", i, movie)movies = append(movies, movie)})return movies}
数据
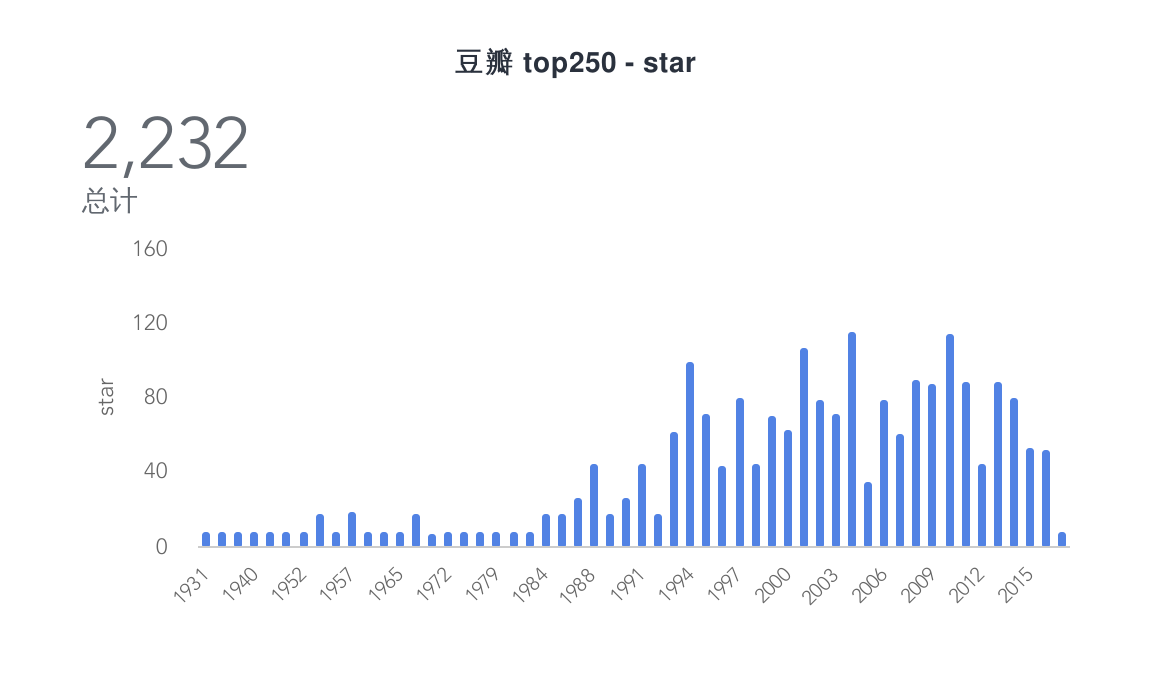
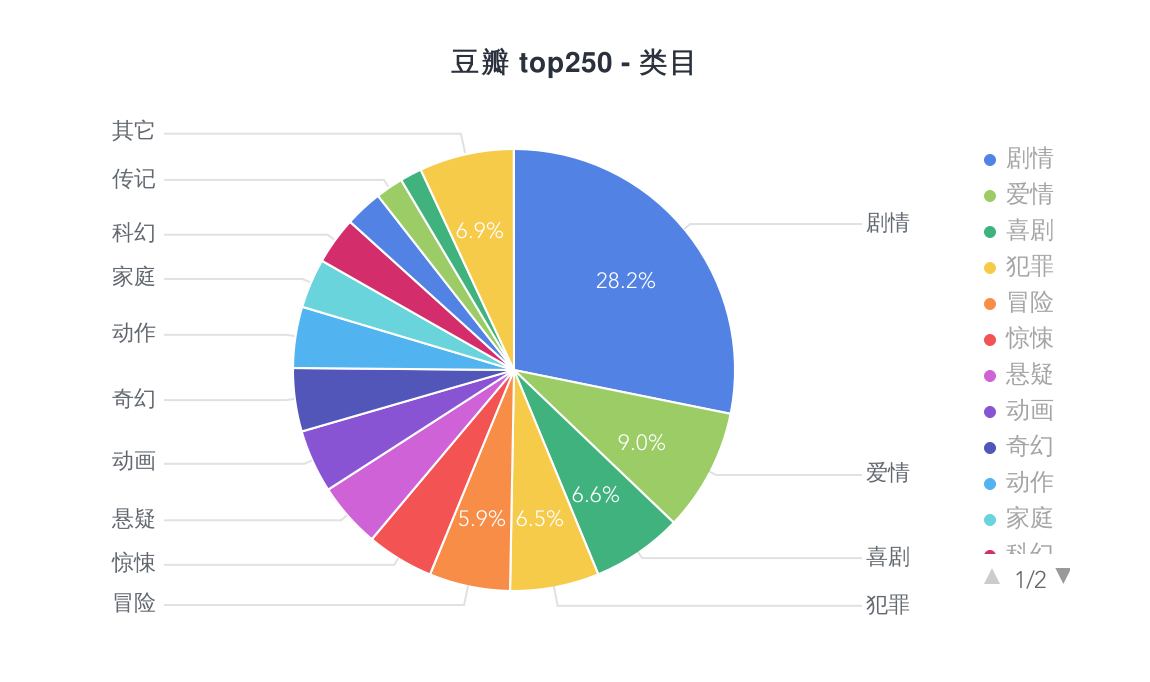

看到这些数据,你有什么想法呢,真是好奇 :=)
