 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 直播问题汇总
- 1、机器学习基础(片刻)
- 2、k-近邻算法(KNN)(小瑶)
- 3、决策树(Decision Tree)(小瑶)
- 4、朴素贝叶斯算法(Naive Bayes)(如果迎着风就飞)
- 5、Logistic 回归(逻辑斯蒂回归)(如果迎着风就飞)
- 6、Support Vector Machine(支持向量机 SVM)(片刻)
- 7、集成方法(ensemble method)(片刻)
- 8、预测数值型数据:回归(regression)(小瑶)
- 9、树回归(小瑶)
- 10、K-Means(K-均值)聚类算法(那伊抹微笑)
- 11、Apriori 算法关联分析(那伊抹微笑)
- 12、FP-growth算法发现频繁项集(如果迎着风就飞)
- 13、PCA 简化数据(片刻)
- 14、SVD 简化数据(片刻)
- 15、大数据与 MapReduce(片刻)
直播问题汇总
标签(空格分隔): 机器学习 直播问题
1、机器学习基础(片刻)
谷德 2017-11-20 20:45:09
问:关于 github ,如果是管理员的话,那只能在 web 页面上做查看和审批吗?不能用 vscode 等编辑器进行吗?答:管理员啥权限都有的,删除和创建项目的权限都有,但是都是在网页上进行, vscode 还不可以。github 的 桌面客户端应该也可以,但是相对用的较少。
HY Serendipity 2017-11-20 20:58:39
问:回归和函数拟合的区别在哪儿?答:回归是预测结果,而函数拟合是预测结果的一个步骤。
Michael❦ 2017-11-20 21:31:26
问:话说 sklearn是啥 三方库么 听说好多次啦答:scikit-learn 简称 sklearn 。是机器学习中一个常用的 python 第三方模块,英文官网:http://scikit-learn.org/stable/ 。中文官网(^_^):http://sklearn.apachecn.org/ 。里面对一些常用的机器学习方法进行了封装,在进行机器学习任务时,并不需要每个人都实现所有的算法,只需要简单的调用 sklearn 里面的模块就可以实现大多数机器学习任务。
HY Serendipity 2017-11-20 21:33:38
问:em,我想问,之后学习算法是调包实现还是自己写代码实现?答:最正确的做法,就是先了解原理之后,再做调包侠,因为咱们谁上来都不想做单纯的调包侠,那样显得咱们也比较 low 。
HY Serendipity 2017-11-20 22:22:19
问:那个我想问一下,比如我从apachecn上fork了一个项目,并且自己clone到了本地,之后apachecn的项目有了更新,我直接在本地pull了apachecn的远程仓库的项目,但是我push是只能push到自己的仓库的,那么我自己的origin仓库的更新操作是怎么实现的呢?答:是这样实现的,这算是一个基本的操作吧。下面我以第一人称来介绍啊。我先从 apachecn 上 fork 了ML项目到了我自己的 github 中,比如我的 github 用户名叫做 chenyyx ,我的项目中就有了一个叫做 ML 的项目,如 chenyyx/ML 。这样,我接下来,使用 git clone https://github.com/chenyyx/MachineLearning.git 命令,就将这个项目 克隆到我自己的本地计算机了。接下来就是我们的重头戏了。
有一点需要知道:我的 git 默认创建的是本地与远程自己的 github (也就是 chenyyx)之间的关联。即,我在本地输入命令 git remote -v 看到的分支,只有一个 origin 分支,并且这个分支指向的是我自己的 github (也就是: https://github.com/chenyyx/MachineLearning),现在可能你会发现一个问题,我现在本地的文件与远程关联,只是与远程的我自己的 github 项目关联,并没有与 apachecn 的项目关联(也就是https://github.com/apachecn/MachineLearning),所以我们还需要创建一个管道来连接我的本地文件与apachecn的项目。创建的命令是(每个单词之间用空格隔开):git remote add origin_ml(分支名称) https://github.com/apachecn/MachineLearning.git(apachecn的远程分支) 。这样就在我本地文件与 apachecn 的远程分支建立了一个管道,可以用来同步 apachecn 的远程更新。使用命令如下:git pull origin_ml 或者麻烦点,使用:git fetch origin_ml 然后再使用 git merge origin_ml/master 这个命令,将远程的 master 分支上的更新与本地合并。(即达到了我的本地与 apachecn 的远程分支同步),然后再输入命令: git push 就可以将我同步提交到 我们自己的 github 上(实际上,就达到了我们的目的,将apachecn 的远程更新与我自己的github同步)。风风 2017-11-21 00:05:22
问:各位大佬,我装了anconda3,那vscode还需要安装Python3吗?答:不需要了,实际上 anaconda3 就是一个 python 的集成环境,它本身集成了很多常用的库,当然里面已经有了 python3 了,就不需要安装了。
2、k-近邻算法(KNN)(小瑶)
谷德 2017-11-21 20:39:38
问:求距离还有其他的算法吗?答:k 近邻模型的特征空间一般是 n 维实数向量空间
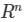 ,使用的距离是欧式距离。当然,我们还可以选择其他距离,比如更加一般的
,使用的距离是欧式距离。当然,我们还可以选择其他距离,比如更加一般的 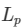 距离(Lp distance),或者 Minkowski 距离(Minkowski distance),曼哈顿距离(Manhattan Distance),切比雪夫距离(Chebyshev Distance)。
距离(Lp distance),或者 Minkowski 距离(Minkowski distance),曼哈顿距离(Manhattan Distance),切比雪夫距离(Chebyshev Distance)。更多参见链接:http://liyonghui160com.iteye.com/blog/2084557
~~ 2017-11-21 20:41:07
问:用来求电影距离的 x y 具体含义是指什么?答:如果大佬你说的是下面这种:
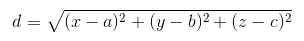
那么求电影距离的 x 是对应的电影中的 打斗镜头数 ,而 y 对应的是接吻镜头数,都是指的数据的特征,可能这里写的不清楚,你可以把这里的 y 当成 x2 属性,而把之前的 x 当成 x1 属性,这样就容易理解多了。都是特征,只不过是对应的不同的特征。注意,这里的 y 代表的不是相应的分类。
如果不是上面的这种,那么 x 代表的就是特征,y 代表的是目标变量,也就是相应的分类。
蓝色之旅 2017-11-21 20:41:22
问:可以讲pearson计算相似评价值度量吗?答:Pearson 相关系数可以参考下面两个链接:
- http://www.codeweblog.com/%E7%9B%B8%E4%BC%BC%E6%80%A7%E5%BA%A6%E9%87%8F-pearson%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0/
- https://www.cnblogs.com/yulinfeng/p/4508930.html
QQ 2017-11-21 20:44:15
问:那这个算法优化点在 k 和 距离上?答:对,但不全对。三个因素上都可以进行优化。
- 比如 k 值的选择上,我们可以选择一个近似误差和估计误差都较好的一个 k 值。
- 距离度量上,我们上面说有很多种的距离度量方式,具体问题具体对待,根据不同的数据我们选择不同的距离度量方式,也可以达到优化的效果。
- 分类决策规则这方面,我们也可以根据自己的经验选择适合的分类决策规则,KNN 最常用的就是多数表决。
- 补充一点,还可以进行优化的部分。可以给训练数据集中的数据点加上适合的权重,距离新数据点相对较近的,权重较大,较远的,权重相应减小。这样也可以算是一种优化吧。
谷德 2017-11-21 21:01:52
问:如果数据的维度很多(列有很多)的话,这个靠内存计算是不是就很快就爆了?答:是的啊,也可能不会爆炸,但是会很慢。当然大佬问的时候说到,那 KNN 在实际应用中的意义何在?之前的巨人们也做了一些相应的优化,比如 kd-tree 和 ball-tree 这些,详细内容可以参见链接:https://www.zhihu.com/question/30957691 。如果你感觉仍然达不到你的需求,对最初的数据进行预处理,也是可以的,比如降维等,在实用算法之前进行一些必要的处理,这样也可以使 KNN 的效率提升。当然,如果还是不如你的预期,那就考虑一下换一个算法试试。
QQ 2017-11-21 21:03:05
问:归一化算法的选取标准是什么?答:归一化算法的选取标准可以参考下面两个链接:
- https://www.zhihu.com/question/20455227
- https://www.zhihu.com/question/26546711/answer/62085061
HY Serendipity 2017-11-21 21:25:18
问:手写数字识别的时候,img2vector 所以是看成了32·32个特征么?答:这么理解稍微有一些偏颇。并不是将图片文件看成 3232 个特征,而是将之前 32 行 32 列的数据转换成为一行数据,也就是 1 1024 的形式,把它当成一条数据来处理,一个图片代表一个样本数据,这样更便于我们接下来的欧式距离的计算。
3、决策树(Decision Tree)(小瑶)
QQ 2017-11-22 20:38:06
问:叶节点是提前分好的吗?答:其实,不能这么说吧,叶节点是根据我们训练数据集中所有数据的分类来得到的,是我们训练出来的。训练数据集中有什么分类,我们就会得到什么叶节点。
HY Serendipity 2017-11-22 20:42:12
问:信息增益是信息熵的差么?答:是的,是数据集划分之前的信息熵 减去 数据集划分之后的信息熵 的差值,得到的这个差值我们就称之为信息增益。
HY Serendipity 2017-11-22 20:45:46
问:什么是划分后熵最小?答:因为我们在构造决策树的过程中,是遍历数据集中所有的数据特征(N个特征,全部都遍历一次),在每一次会依据一个特征划分数据集之后,会计算一下划分后得到的子数据集的新的信息熵。我们从这些得到的新的信息熵中找到那个最小的信息熵,也就是划分数据集之前的信息熵与划分数据集之后的信息熵的差值是最大的。也就是咱们说的信息增益是最大的。
谷德 2017-11-22 20:48:45
问:那树的深度是多少呢?答:在没有设置树的深度,或者没有设置树的停止条件下,树的深度是N,也就是训练数据集的 N 个特征数。
当然树的深度可以自己设置,比如,我们在使用信息增益划分数据集的情况下,我们可以设置信息增益的最小值(作为阈值),只要大于我们设置的最小值就划分数据集,如果小于这个阈值的话,我们就不再划分数据集了。这其实就是一个剪枝的概念(预剪枝)。而既然有这种考虑的话,那我们就要想到,不再划分数据
还有就是在我们已经将树构建完成后,认为树的节点或者深度过多的话,可以通过一定的算法减少树的节点和深度,这样就得到了自定义的树的深度和节点。这也是另一种层面上的剪枝(后剪枝)。
HY Serendipity 2017-11-22 20:55:28
问:这个示例里的特征的概率具体是怎么计算的?还有详细的信息熵计算。答:首先我们看一下计算香农熵的公式,然后下面看计算给定数据集的香农熵的函数。
其中的 $p(x_i)$ 是选择该分类的概率。
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:
H = -\sum_{i=1}^{n}p(x_i)log_2p(x_i)
def calcShannonEnt(dataSet):# 求list的长度,表示计算参与训练的数据量numEntries = len(dataSet)# 计算分类标签label出现的次数labelCounts = {}# the the number of unique elements and their occurancefor featVec in dataSet:# 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签currentLabel = featVec[-1]# 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。if currentLabel not in labelCounts.keys():labelCounts[currentLabel] = 0labelCounts[currentLabel] += 1# 对于 label 标签的占比,求出 label 标签的香农熵shannonEnt = 0.0for key in labelCounts:# 使用所有类标签的发生频率计算类别出现的概率。prob = float(labelCounts[key])/numEntries# 计算香农熵,以 2 为底求对数shannonEnt -= prob * log(prob, 2)return shannonEnt
可以看到,我们这里计算概率纯属就是为计算数据集的香农熵做准备的。接下来,这里是这样来计算相应概率的:1、首先统计 dataSet 中全部数据的条数,作为总数据量(也就是我们要计算概率的时候的除数或者说是分母)。2、然后遍历数据集中的所有数据,统计数据集中的分类,生成一个字典,形式如:{"A(我是分类A)":2(数据集中所有A类数据的条数), "B(我是分类B)":3(数据集中所有B类数据的条数)....}。3、最后遍历这个字典,使用字典中每一项对应的条数除以总的数据量,就计算出相应的概率了。emmm,就这样我们集计算了相应的概率。4、接下来就是计算香农熵,以 2 为底的对数计算。按照我们上面的信息熵计算公式。shannonEnt -= prob * log(prob, 2) 就得到了香农熵了。
不知道讲没讲清楚,也不知道讲没讲错误,还请大家看一下,有什么问题直接联系我(小瑶)。(╯‵□′)╯︵┻━┻
4、朴素贝叶斯算法(Naive Bayes)(如果迎着风就飞)
小瑶 2017-11-23 20:45:05
问:先验概率和后验概率都是什么意思?答:先验概率是在缺乏某个事实的情况下描述一个变量; 而后验概率是在考虑了一个事实之后的条件概率。所以后验概率也可以叫做条件概率。
HY Serendipity 2017-11-23 20:52:56
问:朴素是指条件独立吗?答:是的,朴素贝叶斯就是假设条件完全独立。
那伊抹微笑 2017-11-23 21:16:45
问:为什么概率最大是我们想要的结果?答:代价最小/风险最小(需要详细写一下吧)
超萌小宝贝 2017-11-23 21:20:18
问:两种估计就差一个参数?答:最大似然估计和贝叶斯估计,分母和分子是相差一个参数的,是为了避免概率值为0的情况。但是目的都是为了计算概率。
HY Serendipity 2017-11-23 21:21:01
问:分母为什么要加上分子的 s 倍?答:s倍取决于特征数,因为我要保证所有特征数属于某个类别的概率和为1。
灵魂 2017-11-23 21:30:48
问:拉普拉斯平滑是为了解决什么问题?答:有时候因为训练量不足,会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准(这就引出了我们的拉普拉斯平滑),它的思想非常简单,就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。(不知道回答的对不对)
5、Logistic 回归(逻辑斯蒂回归)(如果迎着风就飞)
HY Serendipity 2017-11-24 21:06:22
问:我不清楚的是这里怎么引出梯度上升的?答:因为逻辑回归在使用sigmoid函数的时候要找到每个特征是某个类别的权重,所以通过梯度上升来找到最优的权重比。
HY Serendipity 2017-11-24 21:19:25
问:为什么要使用梯度上升求极值呢?答:梯度上升和梯度下降都可以用来求极值,我们这里用梯度上升来求某条数据是某个类别的最大的可能性。最大的可能性肯定就是求最大值呀。所以求极大值上升,极小值下降。
ls 2017-11-24 21:26:32
问:什么时候使用梯度上升,什么时候使用梯度下降?答:主要看你的数学问题,和二次方程一样,-x^2肯定有最大值,x^2肯定是最小值啊。
HY Serendipity 2017-11-24 21:35:11
问:我其实更想知道似然函数,因为这里用到了梯度上升答:似然函数就一种条件概率,某个数据是某个类别的概率。
为什么 LR 模型要使用 sigmoid 函数,背后的数学原理是什么?
答:https://www.zhihu.com/question/35322351
6、Support Vector Machine(支持向量机 SVM)(片刻)
HY Serendipity 2017-11-27 20:36:47
问:这几个边界点是怎么选的?答:
ls 2017-11-27 20:43:18
问:函数间距怎么个意思啊?答:函数距离是人为定义的,可以通过缩放w和b任意改变,所以不能用函数间距代表这个点到超平面的距离,用几何距离是一定的。
怎么找最大间隔?
答:分子等于 1,怎么解释?
答:我在网站上看到的公式是乱码? A:github 没加载js,不会显示 LaTex?
答:若果 w 之前没做平方的话,那这里求偏导不就没了?
答:不做平方的话,就不是凸二次规划问题,就不能用拉格朗日替换了。alpha是指什么?
答:拉格朗日乘子这里的C是干嘛的,怎么选择的?
答:不同的核函数,怎么使用?我的意思是什么情况下用什么核函数?
答:
7、集成方法(ensemble method)(片刻)
HY Serendipity 2017-11-28 20:46:03
问:这里的分裂特征是什么?答:
风风 2017-11-28 20:55:44
问:我有个问题,如果都是随机化,那是不是每次运行算法都会不一样?答:
有放回 和无放回区别是什么哦?标准是:是否可以重复取样?
答:怎么使用这些已有代码呢?用于理解这些算法理论?
答:
8、预测数值型数据:回归(regression)(小瑶)
HY Serendipity 2017-11-29 20:42:04
问:最后的表达特征与结果的非线性是什么意思?答:就是说,我们得到数据特征之后,这些特征可能与最终的结果没有关系(或者说有关系,但是是非线性关系),但是我们通过加一些权重,就可以使得特征与我们最终的结果之间有一个线性关系了,这就是我们说的,使用线性数据(特征)来表达非线性关系的意思了。
介绍一下k折交叉验证。
答:K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
Cold 2017-11-29 21:43:42
问:这个回归 应用场景 主要是预测么?答:是的,主要是做预测,根据我们现在已有的一些数据,对接下来我们想要知道(而还未知道)的一些数值型数据做预测的。
9、树回归(小瑶)
片刻 2017-11-30 21:07:31
问:决策树和模型树的区别在哪里?还没听明白答:其实这个问题不能这么说吧。模型树本质上就是决策树的一种。大佬你想问的应该是分类树,回归树,模型树之间的一个区别在哪儿。
- 分类树:在找划分数据集的最佳特征的时候,判断标准是等于不等于(是不是),而不是比较数值之间的大小,并且划分数据集(切分子数据集)的依据是信息增益(划分数据集之前的信息熵减去划分数据集之后的信息熵),测试数据根据我们构建完成的树结构走到最终的叶节点的时候,得到的是我们对测试数据的一个预测分类。
- 回归树:在划分数据集的最佳特征的时候,判断标准是数值之间的大小比较,比如小于等于 value 值的进入左子树,而大于的进入右子树,并且,测试数据根据我们构建完成的树结构走到最终的叶节点的时候,得到的是我们对测试数据的一个预测值(预测值我们使用同一叶节点的均值)。
- 模型树:对数据进行分段预测,只不过存储的子树中,是存储的线性回归模型的回归系数,这样从每个子树中我们就能够得到一个线性回归模型。通俗来说,就是决策树和线性回归的一个结合。
HY Serendipity 2017-11-30 21:22:42
问:后剪枝是将两个叶子变成一个叶子?答:后剪枝是从根节点遍历,一直找到最后的叶节点,然后计算,合并之后的两个叶子节点得到的误差值,与合并之前的两个叶子节点的误差值,做一个差值,看看是否小于我们设定的一个阈值,小于的话,我们就认为可以合并,然后,将两个叶子节点合并成一个叶子节点,并且使用两个叶子节点的所有数据的均值来代表这个叶子节点。
诺 2017-11-30 21:24:11
问:后剪枝需要遍历每个节点吗?答:是的,需要遍历每个节点,从根节点起,一步一步遍历到不是树的节点,也就是最后的叶子节点。然后考虑合并还是不合并。
10、K-Means(K-均值)聚类算法(那伊抹微笑)
小瑶 2017-12-01 20:46:29
问:kMeans 会不会陷入局部最优?答:会陷入局部最优,咱们这里介绍了一个方法来解决这个问题,二分 kmeans 。
11、Apriori 算法关联分析(那伊抹微笑)
2017-12-04 暂时无问题。
12、FP-growth算法发现频繁项集(如果迎着风就飞)
HY Serendipity 2017-12-05 20:41:38
问:感觉这里的支持度有点问题啊,应该是出现次数比较妥当?答:是的,这里我们省略分母,因为我们算支持度=出现次数/总的数目。 分母其实都是一样,所以我们省略了。
HY Serendipity 2017-12-05 21:09:45
问:就是想问一下怎么一步步递归得到最后的t的所有频繁项集?答:就是递归的去构造FP树,然后从FP树中挖掘频繁项集,当FP树节点为空,当前根递归才算结束。
13、PCA 简化数据(片刻)
、 2017-12-06 20:44:01
问:为什么主成分的方向,就是数据方差最大的方向?答:
mushroom 2017-12-06 20:58:54
问:降维之后会损失有效数据,怎么理解?答:
cpp 2017-12-06 20:59:35
问:为什么会正交?答:正交的一个原因是特征值的特征向量是正交的。(还需要详细说一下)
14、SVD 简化数据(片刻)
风风 2017-12-07 21:19:22
问:为什么分解后还要还原?或者说,压缩的目的是什么?答:
15、大数据与 MapReduce(片刻)
HY Serendipity 2017-12-08 20:45:21
问:mrjob 和 hadoop 区别是什么?答:hadoop = HDFS + YARN + MapReduce
