 我的书签
我的书签
 添加书签
添加书签 移除书签
移除书签- 基于用户的协同过滤
- 基于物品的协同过滤
- 能否举个例子?
- 能否举个例子?
基于用户的协同过滤
目前为止我们描述的都是基于用户的协同过滤算法。我们将一个用户和其他所有用户进行对比,找到相似的人。这种算法有两个弊端:
- 扩展性 上文已经提到,随着用户数量的增加,其计算量也会增加。这种算法在只有几千个用户的情况下能够工作得很好,但达到一百万个用户时就会出现瓶颈。
- 稀疏性 大多数推荐系统中,物品的数量要远大于用户的数量,因此用户仅仅对一小部分物品进行了评价,这就造成了数据的稀疏性。比如亚马逊有上百万本书,但用户只评论了很少一部分,于是就很难找到两个相似的用户了。
鉴于以上两个局限性,我们不妨考察一下基于物品的协同过滤算法。
基于物品的协同过滤
假设我们有一种算法可以计算出两件物品之间的相似度,比如Phoenix专辑和Manners很相似。如果一个用户给Phoenix打了很高的分数,我们就可以向他推荐Manners了。
需要注意这两种算法的区别:基于用户的协同过滤是通过计算用户之间的距离找出最相似的用户,并将他评价过的物品推荐给目标用户;而基于物品的协同过滤则是找出最相似的物品,再结合用户的评价来给出推荐结果。
能否举个例子?
我们的音乐站点有m个用户和n个乐队,用户会对乐队做出评价,如下表所示:
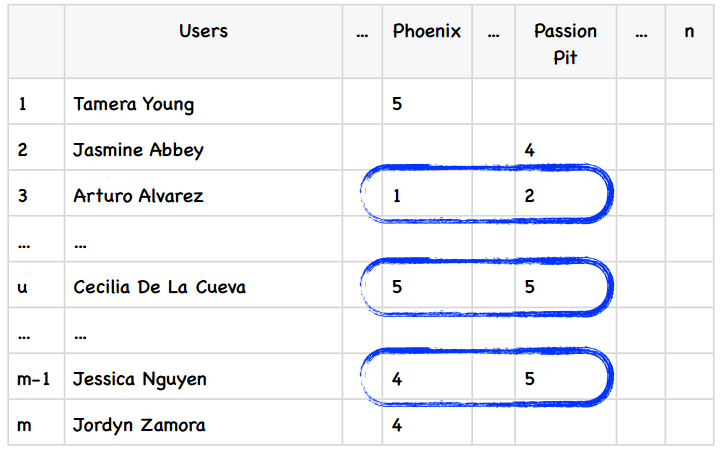
我们要计算Phoenix和Passion Pit之间的相似度,可以使用蓝色方框中的数据,也就是同时对这两件商品都有过评价的用户。在基于用户的算法中,我们计算的是行与行之间的相似度,而在基于物品的算法中,我们计算的是列与列之间的。

基于用户的协同过滤又称为内存型协同过滤,因为我们需要将所有的评价数据都保存在内存中来进行推荐。
基于物品的协同过滤也称为基于模型的协同过滤,因为我们不需要保存所有的评价数据,而是通过构建一个物品相似度模型来做推荐。
